Today’s DevTest teams are under pressure to deliver more (and more innovative) software faster than ever before. And now that most organizations are relying on software as a primary interface to the customer, compromising on quality to accelerate a release is not an option.
How can DevTest teams deliver “quality at speed”? Unfortunately, there’s no silver bullet. However, one essential element is to have unrestrained access to a realistic test environment (e.g., including the AUT and all of its dependent components). Otherwise, you can’t accurately and thoroughly validate the change impacts associated with each user story, or be confident that the evolving application doesn’t degrade the overall user experience. Access to a complete test environment not only helps you achieve greater velocity, it also enables you to assess the risk of a release candidate during a Continuous Integration/Continuous Delivery process, and identify high-risk release candidates early in the delivery pipeline.
However, with today’s complex systems, this type of test environment access is the exception rather than the rule. Testing in production is one way to access a 100% realistic test environment, but this approach is typically frowned upon for a number of reasons. In fact, in a recent poll, only 12% of the 316 respondents were allowed to test in production.
Although it was once common for organizations to stand up a local physical staged test environment, the complexity of modern applications has made that approach too slow and cost-prohibitive for today’s development processes. Consider the following statistics:
The average time to provision a DevTest environment is 18 days (according to Voke: “Research, Market Snapshot Report: Virtual and Cloud-Based Labs”)
After that, the average time required for configuration is 12 to 14 days
The average investment for a pre-production lab is US$12 million
Seventy-nine percent of teams face third-party restrictions, time limits, or fees when trying to access the dependencies required for development and testing
Teams need access to an average of 52 dependencies in order to complete development and testing tasks, but the majority have unrestricted access to 23 or fewer
Given these constraints, it’s not surprising that 81% of development teams and 84% of QA teams experience delays due to limited test environment access.
Today, technology has advanced to the point where it’s possible to make realistic simulated test environments available on demand. With technologies like cloud (for elastic scalability), containers (for rapid deployment), and service virtualization (to simulate and access dependencies), there’s no reason why a complete, realistic test environment should be out of reach.
This is where a “Deploy and Destroy” strategy comes in.
What is Deploy and Destroy?
Essentially, Deploy and Destroy is the ability to rapidly deploy a complete test environment in less than 10 minutes. The most realistic dependent components (APIs, third-party services, databases, applications, and other endpoints) that are available at that specific point in time are aggregated from a central repository and then provisioned automatically. The “most realistic set of dependent components” is often a combination of both real components and simulated components delivered via service virtualization.
A Deploy and Destroy environment is lightweight and cloud-compatible so that when you need to scale (e.g., for performance testing), you can do that on demand. A Deploy and Destroy environment is also disposable. It can be instantly provisioned from a golden template, used and dirtied, then simply destroyed. There’s no need to spend time resetting the environment or test data to its original state. The exact same environment can be instantly spun up whenever it’s needed (e.g., for reproducing or verifying defects).
A technical look at deploy and destroy
The first step in Deploy and Destroy is building up a library of service virtualization assets. This is typically done by recording interactions with a live application, but it can also be accomplished by other means (from Swagger or other definitions, from traffic files, and so on). If desired, you can extend and enhance these assets with additional data, performance profiles, response logic, etc.
Once you’ve established a foundational set of service virtualization assets, you can aggregate them into what we call an environment. From a core system blueprint, an environment defines what states each of the AUT’s dependencies can adopt. For instance, one of the environment’s third-party services might be represented by 10 different virtual versions of that service, each with different combinations of performance and data profiles, as well as the real version of that same service. Environments with any combination of these dependency configurations can then be provisioned on demand (e.g., a virtual API simulating network congestion and error responses and a real database and a virtual mainframe that’s returning positive responses).
To further streamline and accelerate the provisioning process, you’ll want to pair the deployable environments with container technology such as Docker. This allows you to package the environments and deploy them onto running containers, making complete test environments available in a matter of seconds. The following diagram shows one way that you can use containers to enable the Deploy and Destroy strategy:
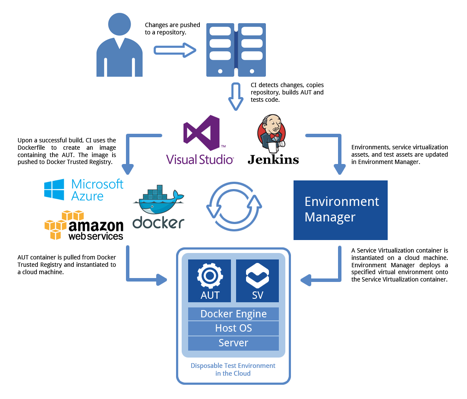
Deploy and Destroy in action
For an example of how Deploy and Destroy is applied in the real world, consider the following case study. An enterprise software division’s leaders were confident that thoroughly testing each user story as soon as it was completed would help them achieve their goals of a) delivering more business value in each of their two-week agile sprints, and b) finding defects earlier in the SDLC. However, limited access to test environments that accurately represented their disparate systems made it difficult to exercise the required end-to-end transactions as early and often as needed.
Virtually all of the 200 applications that this group is responsible for have a complex set of dependencies, including direct interaction with the company’s multibillion-dollar sales portal. Accurately testing realistic end-to-end transactions across these applications requires access to a complete test environment, including many different internal and external systems communicating with an assortment of protocols and message formats. Further complicating matters, their test plans require that each user story be tested versus dependencies that are configured with extremely specific test data, response logic, and performance conditions—and configuring the environment for one user story means disrupting the configuration for the others. Moreover, since the company performs parallel development, tests sometimes involve services that are not yet implemented or are still evolving during the current iteration.
Recognizing that the ability to observe the request and response transactions emanating from the application under test was key to providing a simulated test environment, the QA Architect used service virtualization to observe this transaction traffic. This exposed the scope of dependent systems associated with the application under test. With dependencies identified, the QA Architect was able to create a library of service virtualization assets that simulated the observed behavior.
Now that the building blocks of the simulated test environment have been defined, DevOps engineers configure simulated environment instances as part of the automation tool chain, allowing developers and testers to define, exercise and continuously execute automated tests. These environment instances are automatically deployed to Microsoft Azure VMs during the build phase of the Microsoft Visual Studio Team System pipeline. After automated tests are completed, a similar Microsoft VSTS build definition destroys each test environment.
Applying the Deploy and Destroy strategy enables them to simultaneously spin up the various test environments required to test each user story from the moment it’s completed. This helps them quickly expose and address problems with new functionality before the end of each sprint—as well as to continuously execute a robust regression suite that alerts them immediately if code changes break existing functionality.
Now that the team can immediately and continuously test each user story against a complete, realistic test environment, their sprints are not only more predictable (with fewer carryover user stories), but are also more productive (with increased velocity). Most importantly, this increased delivery speed does not require any tradeoff at the expense of quality.
In fact, quality has actually improved. Previously, only 30% of their defects were being discovered within the delivery pipeline. Now, the vast majority of defects are identified and resolved before the user story is deemed “done done.”
Overall, the team achieved the following results by applying Deploy and Destroy:
Early and continuous testing
The organization knew that Azure DevTest environments could help them provide immediate access to the application stacks, which could be logically imaged (as long as they had configuration control). However, they still needed another strategy to provide access to the functionality of the continuously evolving sales portal, as well as the hundreds of other services and third-party applications beyond their control for traditional server virtualization. These dependencies spanned a range of technologies, including Salesforce, Sabrix, DataPower, CFS file format, PayPal, Blaze front-end optimization technology, multiple databases (Oracle, ADO, DB2, SQL Server), MQ, and WebLogic.
By adding service virtualization and Deploy and Destroy to the mix, the DevTest teams were able to instantly and simultaneously access the realistic, flexible test environments needed to execute a broader array of end-to-end tests. Their testing could begin as soon as each user story was completed, and myriad user stories could be validated simultaneously during Continuous Testing—each with the specific test environment required for the associated tests.
Greater flexibility
Deploy and Destroy—in particular, service virtualization’s simulation—allowed the DevTest teams to provision test environments with more flexibility than staged test environments could provide. With a physical staged test environment, they couldn’t feasibly manipulate the behavior or performance of many dependent applications (for example, mainframes or ERPs). They would have to deal with hardware, configuration settings associated with the allocation of memory or the allocation of VM configuration resources, and so on.
After adopting Deploy and Destroy, the teams could readily access a core library of 500+ service virtualization assets that provide flexible, on-demand access to the behavior of the many dependencies required to exercise realistic end-to-end transactions. These virtual assets were built by capturing actual behavior and architected so that they can be easily updated to reflect changes in the dependencies, as well as extended to cover any additional conditions that need to be simulated for testing a particular user story. For example, response logic, data, and performance conditions can all be reconfigured instantly, even by novice team members. This helped them test extreme cases (e.g., for concurrency issues or outages, resiliency and failover, load balancer issues, and so on).
Greater consistency and accuracy
To orchestrate Deploy and Destroy, the organization established an infrastructure that would automatically spin up complete cloud-based DevTest environments tailored for testing each user story. Since the infrastructure enables multiple test environments to be active simultaneously (with any given test environment having zero impact on the other test environments simultaneously being used to validate other requirements), they were termed “bubbles.” These bubbles are automatically provisioned whenever they’re needed, then destroyed as soon as the associated testing is completed. In other words, they are dynamic yet disposable. Moreover, any time that a virtual asset is modified (e.g., if a service introduces a new operation), the “master copy” is updated in source control, then the updated virtual asset is automatically used in bubbles from that point forward.
With Deploy and Destroy, everyone is always on the same page, accessing the latest and greatest data, virtual assets, test assets, etc. Each time a test environment is provisioned, it is created from scratch using the master set of data, virtual assets, test artifacts, etc. stored in the repository. This makes it impossible for tests to be executed against “dirtied” test environments by using outdated test data, versus an unauthorized version of a virtual asset, and so on.