
Canonical has officially released Charmed MLFlow, their version of the well-known machine learning platform. Charmed MLFlow is designed for tasks like model registry and experiment tracking and seamlessly integrates with AI and big data tools like Apache Spark and Kubeflow. It’s flexible and can be deployed on various infrastructure types, from workstations to public and … continue reading

Today, IBM released the Open Source Cloud Guide which highlights various use cases that are important in hybrid cloud environments and features the important open-source projects in those areas. The guide offers an overview of the concept or use case, an explanation of a traditional solution to achieve it, key open-source projects, and a highlight … continue reading
The Apache Drill Project announced the release of Apache DrillTM v1.19, the schema-free Big Data SQL query engine for Apache Hadoop, NoSQL, and Cloud storage. “Drill 1.19 is our biggest release ever,” said Charles Givre, the Vice President of Apache Drill. “With an already short learning curve, Drill 1.19 makes it even easier for users … continue reading
CodeFlare is IBM’s open-source framework that simplifies the integration and scaling of big data and AI workflows onto the hybrid cloud. It drastically reduces the time to set up, run, and scale machine learning tests and expands on the functionality of Ray. Also, CodeFlare pipelines run with ease on IBM’s new serverless platform IBM Cloud … continue reading
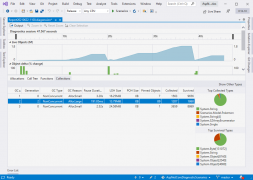
The .NET Object Allocation Tool received new features and a significant performance boost as of the Visual Studio 16.10 release. The tool now has support for Source Link which lets the tool pull down source files, showing where allocations are occurring even when they are not in your code. Search now has auto-complete suggestions to … continue reading

Apache DolphinScheduler, the distributed Big Data visual workflow scheduler system, is the latest project to gain Top-Level Project status at the Apache Software Foundation (ASF). This means that the project’s community and products have been well-governed under the Apache Software Foundation’s meritocratic process and principles. The scheduler was first created in December 2017 at Analysys … continue reading
The Apache Software Foundation (ASF) announced that Apache Gobblin, the open-source distributed Big Data integration framework, has reached top-level project status. According to the foundation, achieving top-level status means that the project graduated from the Apache Incubator and has demonstrated that it’s community and products have been well-governed under the ASF’s meritocratic process and principles. … continue reading

Swap Detector is an open-source checker that detects API usage errors. The project was released this week by GrammaTech, and originally created by The Department of Homeland Security, Science and Technology Directorate, and Static Tool Analysis Modernization Project. “Traditional static-analysis techniques do not take advantage of the vast wealth of information on what represents error-free … continue reading
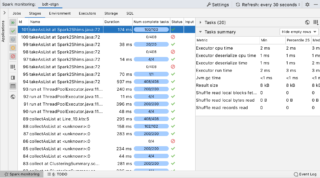
JetBrains announced that Big Data Tools is now available as EAP for DataGrip and PyCharm Professional. The news aims to address problems that involve both code and data. The company first announced plans to support more big data tools last year when it announced a preview of the IntelliJ IDEA Ultimate plugin with Apache Zeppelin … continue reading
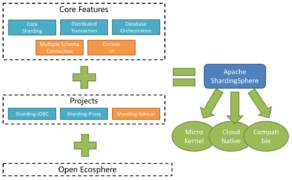
The Apache Software Foundation announced that Apache ShardingSphere, a distributed Big Data middleware ecosystem, has now graduated to a Top-Level Project. “Since entering the Apache Incubator, ShardingSphere has evolved from a JDBC driver for sharding into a distributed ecosystem,” said Liang Zhang, the vice president of Apache ShardingSphere. The Apache ShardingSphere ecosystem has 3 sub-projects … continue reading
The Apache Software Foundation (ASF) graduated Rya, a scalable open-source Big Data database, to its list of Top-Level Projects (TLP). The project was submitted to the Apache Incubator in September 2015. The database is triple store (subject-predicate-object) database, and is capable of storing billions of linked information sets by using novel storage methods, indexing schemes … continue reading
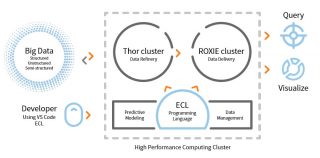
HPCC Systems (High Performance Computing Cluster), a dba of LexisNexis Risk Solutions, is an open-source big-data computing platform. Flavio Villanustre, vice president technology and CISO at LexisNexis Risk Solutions, explained HPCC Systems’s evolution came as a necessity. “In 2000 we were getting into data analytics, using the platforms, databases, and data integration tools that were … continue reading