Over the last 12 to 18 months, a growing trend has emerged in the cloud space. Just a few years back, we were accustomed to using a bare metal server for each application—then we evolved to Hypervisors and virtualization to squeeze more out of our physical resources. The next step was to squeeze even more by splitting those VMs and instances into smaller units—containers. We are now seeing the next stage in that evolution—Function as a Service—or, as it is more commonly known, serverless.
The Rationale
We are continually looking to optimize our resource usage and costs, and what better way to do so than to eliminate the underlying operating system? Essentially, what most of us do is write code to create applications. We don’t want to manage operating systems and their dependencies, or to have to orchestrate all of these. We write code, and expect that the code will run—as is—without having to deal with all the plumbing underneath. This is where serverless comes into play.
The Pioneers—AWS Lambda
As is the case is with many of the things we use today in the public cloud, Amazon were the pioneers in offering this functionality, with Lambda. The basic concept of Lambda is to allow you to upload your code (which of course has to be in one of the supported languages) without having to worry how it deploys or scales—all of this is taken care of by the platform. Your code will run based on the triggers you define, which can be anything from messages in a queue to scheduled tasks—there is a great deal of flexibility allowed. The best thing about this is that you are only billed for the time that your function is actually in use—and the amount of resources you allocate to it. No more paying for hours of computer resources and storage just because your code needs to run 12 times a day. The granularity available to you is so fine that honestly, unless you are an extremely heavy user, your costs will probably fit into the free tier available from Amazon (first 1 million requests per month for free).
What About OpenStack?
There are many things in OpenStack that are not available as full-fledged services and that are not as robust as their counterparts in AWS. LBaaS and DBaaS are two examples of what the OpenStack community has tried to produce over a number of years. Unfortunately, these services are not on par with their competitors, and many enterprises refuse to adopt them because of a lack of basic functionality, even after a number of cycles.
The OpenStack community has recognized the trend toward serverless infrastructure and that there will be (and is) a demand for such a service in OpenStack as well. Currently, there are two competing projects offering FaaS on OpenStack, both of which are backed by commercial companies.
StackStorm
StackStorm define their product as an “event-driven automation platform” and presented a session at the last OpenStack Summit in Boston.
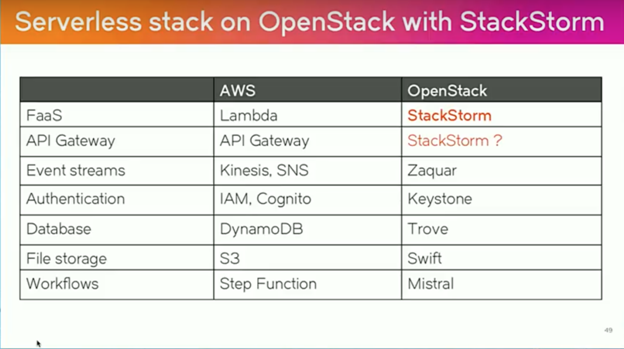
(Source: StackStorm presentation—OpenStack Summit Boston)
As you can see above, the solution itself makes use of a number of other OpenStack services, such as Zaquar, Trove, and Mistral. The problem is that the majority of today’s OpenStack deployments hardly use any of these services in production, as you can see below:
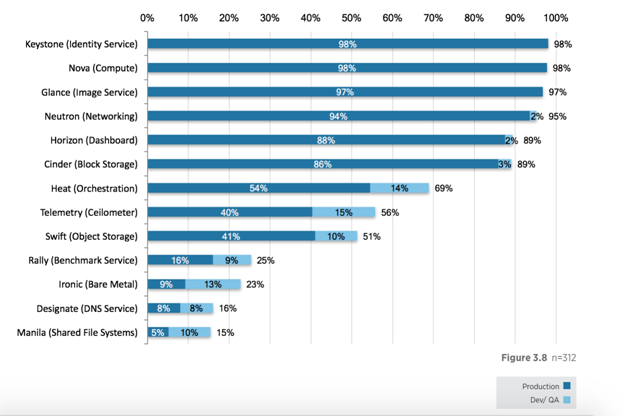
(Source: OpenStack User Survey 2017)
Going down the StackStorm route therefore entails a lot of tinkering, and in many ways is a journey into uncharted waters, since this has not been accepted as a proper OpenStack project.
OpenWhisk
OpenWhisk is an IBM project that was also demonstrated at the Boston OpenStack Summit. The project is open-source, and one would assume that it is looking to become the de facto solution for serverless on OpenStack (and perhaps also on-premises) clouds in the modern data center. The example that was presented in the Boston session was based on the specific scenario of a file upload to Swift, which would then trigger a function on OpenWhisk:
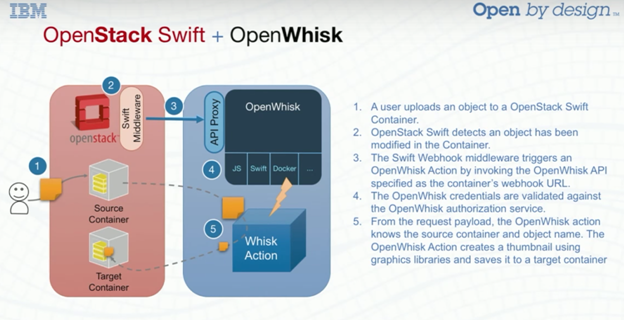
(Source: OpenWhisk presentation—OpenStack Summit Boston)
Maturity
As you can see from the two presentations and examples above, serverless is still a work in progress. The OpenStack community itself has yet to decide which one of the solutions they would like to converge upon to provide a fully integrated serverless solution for OpenStack. The examples above should not be considered fully fledged solutions that anyone could actually use on their OpenStack (or on-premises) cloud today.
Will Serverless Swallow Private Cloud?
More and more enterprises are moving their workloads to the major public cloud providers (AWS, Azure, and Google) because the pace at which OpenStack is progressing is too slow.
This doesn’t necessarily have anything to do with serverless, but rather with aaS functionality as a whole. FaaS will always need some underlying infrastructure to run the actual code—there is no magic involved—and there will always need to be an operating system underneath. It is a question of how seamless and invisible you make it to the end user (Lambda, Google Cloud functions, and Azure functions are very good examples of how this can be implemented at scale today) and how you can tie this service into all the other offers you have in your cloud.
Summary
Cloud professionals would suggest that, if possible, you wait a few more cycles to allow the open-source products and offerings to mature to the point where they can be used in a simple and harmonious way, so that yours is not one of the first companies actually trying to use these products in a private cloud solution.
If you have an immediate need, you would be better advised to go with one of the major cloud providers, particularly if they are already running your workloads. Take note that not all of the providers are compatible with each other—and that migrating from one solution to another can be a really complicated operation.