Data is the information that drives business. It can be structured in rows and columns, like a customer name, address, and phone; and it can be unstructured, such as an email or a social media post. Structured data is what is populated in Relational Database Management Systems such as those created by Oracle, IBM and Microsoft, and open-source PostgreSQL and MySQL, among others. That data can be accessed using the standard Structured Query Language (SQL). Unstructured data resides in what are called NoSQL databases, such as Cassandra, Couchbase, MongoDB and many, many others. Many organizations today run both kinds of databases.
Once the data is stored, it must be easily retrievable, found amid the mountains of data organizations collect, and made available at scale. Numerous tools exist for those jobs, including Hadoop, Apache Spark and many more. It is through the collection and analysis of data that businesses can make decisions that affect their bottom line.
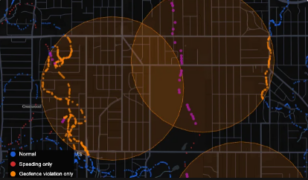
Wherobots is launching a set of features designed to make its powerful geospatial processing capabilities accessible to modern AI systems. Building on its core compute engine — the Wherobots DB, which processes two-dimensional data like map and trip information; and its raster flow tool, which handles aerial imagery data from satellites and drones — Wherobots … continue reading

The Model Context Protocol (MCP) was created to enable AI agents to connect to data and systems, and while there are a number of benefits to having a standard interface for connectivity, there are still issues to work out regarding privacy and security. Already there have been a number of incidents caused by MCP, such … continue reading

Quest Software today announced the Quest Trusted Data Management Platform, unifying data modeling, data cataloging, data governance, data quality, and a data marketplace to enable organizations to deliver AI-ready data throughout their business. It can be leveraged to create a single, unified data product that will be usable by different departments throughout the organization as … continue reading

Box announced the launch of Box Extract, which intelligently pulls information from content and saves it as metadata, helping organizations automate workflows and accelerate decision-making by making information more easily accessible. According to the company, a lot of organizational knowledge lives in contracts, product specifications, policy documents, charts, and other types of unstructured content. Box … continue reading

As this year comes to a close, many experts have begun to look ahead to next year. Here are several predictions for how companies will manage their data in 2026. Sijie Guo, CEO of StreamNative A fundamental shift is happening in how we think about data engineering. For decades, data engineers prepared data for human … continue reading

Despite companies wanting to implement AI and reap the benefits of it, a majority don’t have the underlying foundations in place to make it work well. According to CData’s latest report, The State of AI Data Connectivity: 2026 Outlook, there is a clear link between data infrastructure maturity and AI maturity. The report found that … continue reading

CIOs and CTOs have heard the same refrain for years on end: before you can deploy AI, you need to clean and unify your data. That belief made sense in the era of legacy machine learning, when reductive models required meticulous preprocessing and endless consulting hours. Vendors and integrators built entire business models on that … continue reading

In an increasingly interconnected business world, being able to connect business intelligence (BI) tools to internal applications or data sources is a must. Fortunately, much of the industry has standardized around REST APIs, which provides a starting point for making these connections, but it’s not a perfect system as it stands today. Progress Principal Sales … continue reading

Elastic has introduced a new disk-friendly vector search algorithm, called DiskBBQ, to Elasticsearch. According to the company, this new algorithm is more efficient than traditional search techniques in vector databases, like Hierarchical Navigable Small Worlds (HNSW), which is currently the most commonly used technique. With HNSW, all vectors are required to reside in memory, which … continue reading
Harness is on a mission to make it easier for developers to do database migrations with its new AI-Powered Database Migration Authoring feature. This new capability allows users to describe schema changes in natural language to receive a production-ready migration. For example, a developer could ask “Create a table named animals with columns for genus_species … continue reading

Sonar, a company that specializes in code quality, today announced a new solution that will improve how LLMs are trained for coding purposes. According to the company, LLMs that are used to help with software development are often trained on publicly available, open source code containing security issues and bugs, which become amplified throughout the … continue reading

Companies today want to leverage their data to support business intelligence (BI) initiatives, but without the proper data connectivity processes and tools in place, that data could remain locked in silos. Enter the Progress DataDirect Hybrid Data Pipeline (HDP) connectivity solution, which allows companies to securely connect cloud and on-premises data to BI tools. The HDP … continue reading