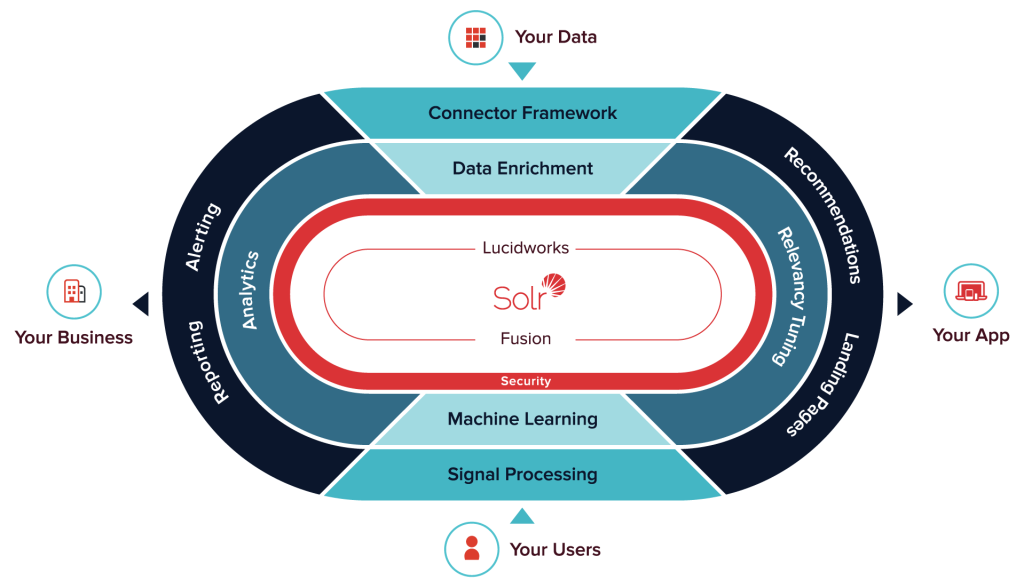
Lucidworks has released version 2.0 of Fusion, its enterprise Big Data search product built on Apache Solr storage architecture, with Apache Spark integration and a revamped SiLK dashboard.
Fusion 2.0’s Spark integration within its data-processing layer enables real-time analytics within the enterprise search platform, adding Spark to the Solr architecture to accelerate data retrieval and analysis. Developers using Fusion now also have access to Spark’s store of machine-learning libraries for data-driven analytics.
(Related: Spark turns heads at Big Data TechCon)
“Spark allows users to leverage real-time streams of data, which can be accessed to drive the weighting of results in search applications,” said Lucidworks CEO Will Hayes. “In regards to enterprise search innovation, the ability to use an entirely different system architecture, Apache Spark, cannot be overstated. This is an entirely new approach for us, and one that our customers have been requesting for quite some time.”
The new Fusion Dashboard leverages Lucidworks’ SiLK responsive UI framework for creation and sharing of data visualizations and to search application performance reports. The dashboard reconfigures Fusion’s user experience by merging pre-existing user interfaces into one for a simplified Apache Solr workflow.
The 2.0 release also enhances Fusion’s facet management with information display customization, along with new security integrations allowing developers to use Kerberos, Active Directory, LDAP and SSO systems to manage authentication to Fusion, assign users to Fusion roles and automatically limit search results according to existing enterprise security groups.
Lucidworks is the commercial sponsor of the open-source Apache Lucene and Apache Solr projects. In integrating Apache Spark with Fusion, Hayes said Lucidworks looked for a way to fold an analytics engine into exposed back-end APIs for users to naturally extend Solr’s capabilities with features such as in-memory caching and optimized execution.
“Fusion 2.0 combines the most powerful open-source tools for Big Data: Apache Solr as the primary data store and retrieval tool, and Apache Spark as the primary analytics engine,” said Hayes. “With the addition of Spark, Fusion can process data streams and signals from millions of users in real time. The goal of including Spark and Solr in our architecture is to empower users to write and run a variety of jobs while taking advantage of both projects’ powerful features and rich libraries in tandem. The experience using these libraries in Fusion should be seamless to the user as it combines these various capabilities into one powerful development platform.”
Fusion 2.0 is available on-premise, multi-tenant and in the cloud through the AWS Marketplace, and it ships with Solr 5.x to support running Fusion against Solr 5.x clusters. Hayes said going forward Lucidworks would focus its continued Fusion development on:
- Security improvements: Including easier configuration of encryption and keys.
- More analytics APIs: In order to apply different types of analysis to data using Apache Spark.
- Data source preview UI: Will enable easier configuration and capture of custom data formats.
- Natural language processing: Integrations, intentions and an answering engine; integrations with deep learning frameworks.
- Node monitoring, and management interfaces and tools.
“Fusion 2.0 cements Lucidworks’ shift from an open-source consultancy to an enterprise platform that powers Big Data search for some of the world’s largest brands,” said Hayes. “Driving the platform’s newest upgrades is the belief that users should be empowered to create experiences around their data, regardless of technological skill. With the release of Fusion 2.0, we have created an entirely new user experience focused on enabling all users to craft a custom data experience within their applications.”




