
Spark. It’s what many organizations are finding that AI can do for their digital transformation efforts. It’s also the theme of the 2025 Broadcom Value Stream Summit, at which the company will present its strategies and tooling for delivery customer value and service. The last major push for digital transformation was fueled by the COVID-19 … continue reading

Software testing company Code Intelligence today announced Spark, an AI test agent that can identify bugs and vulnerabilities without human interaction. In its beta period, for instance, Spark found a vulnerability in WolfSSL where the only human involvement was running a single command to launch the agent. The agent handled analyzing the code, generating a … continue reading

The term Big Data has been bandied about since the 1990s. It was meant to reflect the explosion of data – structured and unstructured — with which organizations are being deluged. They face issues that include the volume of data and the need to capture, store and retrieve, analyze and act upon that information. Technologies … continue reading
Indeed Hiring Lab has just published a report that analyzes two years of tech job search traffic. It combined job search traffic with resume search traffic to determine how popular certain tech skills are with employers. “Technology is progressing at a breakneck pace these days. Software developers, engineers and other tech workers have to work … continue reading

The Apache Foundation this morning announced the promotion of Apache Beam to the top level. That’s good news for the many contributors and users of this unified programming model, which allows them to write batch and streaming jobs at the same time, and to run the resulting artifact on various execution engines. Within the Hadoop … continue reading

Work on Apache Arrow has been progressing rapidly since its inception earlier this year, and now Arrow is the open-source standard for columnar in-memory execution, enabling fast vectorized data processing and interoperability across the Big Data ecosystem. Background Apache Parquet is now the de facto standard for columnar storage on disk, and building on that … continue reading

Redis and Spark are coming a bit closer together. Redis Labs today announced a new project, Redis-ML, to bring Spark-based machine learning capabilities to the Redis database. The combination will provide a faster place to store a trained Spark machine learning model. Redis-ML is hosted on GitHub and will be demonstrated at the Big Data … continue reading
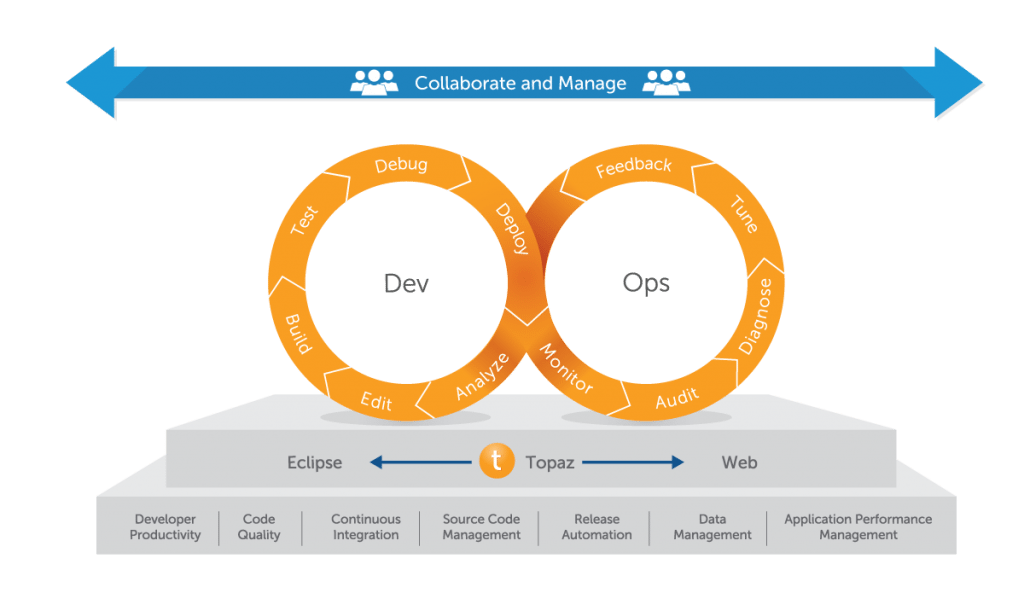
Compuware is extending its mainframe/DevOps initiatives with the availability of new REST APIs for ISPW, its source-code-management and release automation solution that Compuware acquired in January. The new APIs are architected as REST web services, and with these APIs, Compuware customers can begin to accelerate cross-platform apps, reduce IT costs, and improve the quality of … continue reading

MongoDB wants to empower developers to do more with its NoSQL database. The company unveiled MongoDB Atlas and MongoDB Connector for Apache Spark at its third annual MongoDB World conference in New York City today. “When people free their mind and focus on the problem or task at hand, you can do your best thinking,” … continue reading

With the release of Databricks Community Edition today, and the kicking off of the second day of Spark Summit in San Francisco, the Apache Spark project is a hot topic. Underneath the hood, the update brings many changes and improvements to the platform, and at Databricks’ Summit, these were discussed at length. To get a … continue reading

Companies like Amazon, Baidu, IBM and Microsoft were all at Spark Summit this week to discuss how they used the engine. Some of those companies even had new Spark-based products to show off. IBM, for example, introduced a data-centric development environment, which will be able to support machine learning with the R language thanks to … continue reading
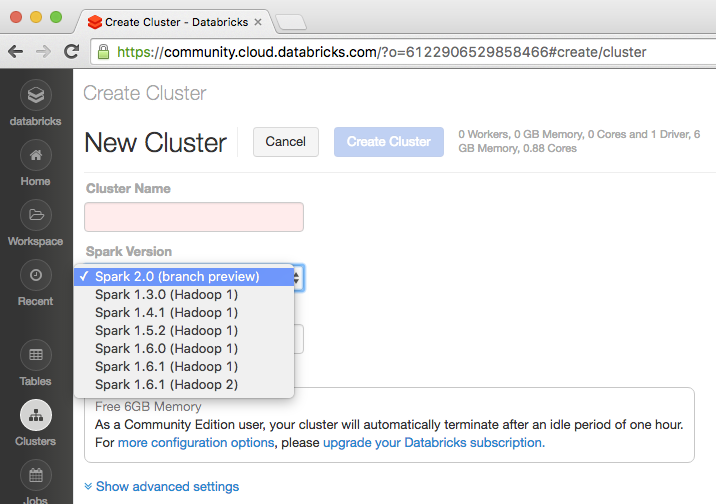
It’s been two years since Apache Spark 1.0 was released, and today Databricks is giving everyone a preview for what is to come in version 2.0. According to the company, the upcoming version focuses on three major themes: easier, faster and smarter. “Spark 2.0 builds on what we have learned in the past two years, … continue reading