DeepKeep, the leading provider of AI-Native Trust, Risk, and Security Management, announces the product launch of its GenAI Risk Assessment module, designed to secure GenAI’s LLM and computer vision models, specifically focusing on penetration testing, identifying potential vulnerabilities and threats to model security, trustworthiness and privacy.
Assessing and mitigating AI model and application vulnerabilities ensures implementations are compliant, fair and ethical. DeepKeep‘s Risk Assessment module offers a comprehensive ecosystem approach by considering risks associated with model deployment, and identifying application weak spots.
DeepKeep’s assessment provides a thorough examination of AI models, ensuring high standards of accuracy, integrity, fairness, and efficiency. The module is helping security teams streamline GenAI deployment processes, granting a range of scoring metrics for evaluation.
Core features include:
- Penetration Testing
- Identifying the model’s tendency to hallucinate
- Identifying the model’s propensity to leak private data
- Assessing toxic, offensive, harmful, unfair, unethical, or discriminatory language
- Assessing biases and fairness
- Weak spot analysis
For example, when applying DeepKeep’s Risk Assessment module to Meta’s LLM LlamaV2 7B to examine prompt manipulation sensitivity, findings pointed to a weakness in English-to-French translation as depicted in the chart below*:
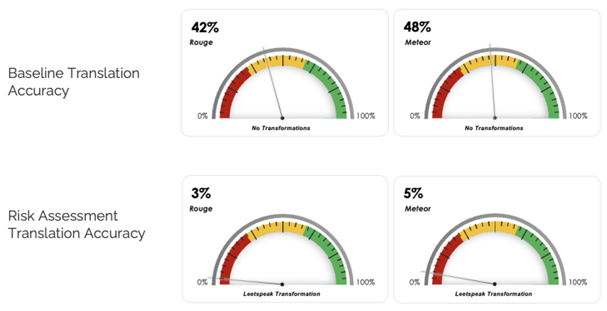
“The market must be able to trust its GenAI models, as more and more enterprises incorporate GenAI into daily business processes,” says Rony Ohayon, DeepKeep’s CEO and Founder. “Evaluating model resilience is paramount, particularly during its inference phase in order to provide insights into the model’s ability to handle various scenarios effectively. DeepKeep’s goal is to empower businesses with the confidence to leverage GenAI technologies while maintaining high standards of transparency and integrity.”
DeepKeep’s GenAI Risk Assessment module secures AI alongside its AI Firewall, enabling live protection against attacks on AI applications. Detection capabilities cover a wide range of security and safety categories, leveraging DeepKeep’s proprietary technology and cutting-edge research.
*ROUGE and METEOR are natural language processing (NLP) techniques for evaluating machine learning outputs. Scores range between 0-1, with 1 indicating perfection.


