
Are your developers on PagerDuty? That’s the core question, and for most teams the answer is emphatically “yes.” This is a huge change from a few years ago when, unless you did not have DevOps or SRE teams, the answer was a resounding “no.” So, what’s changed? A long-term trend is happening across large and … continue reading

Detected Risks can help SREs find and fix common hidden risks that could impact reliability. It flags things that could potentially be failure points, and offers recommendations on how to resolve them. According to Gremlin, the hope with this new solution is that it empowers companies to transition from “reactive problem-solving to proactive risk mitigation.” … continue reading
Platform engineering has become increasingly important for businesses as platforms have become more complex, spanning DevOps tools, APIs, and other components necessary for effective software development. It’s a delicate balancing act as developers have been calling for more simplified navigation throughout an organization’s platform. According to a whitepaper by Humanitec, just five years ago, platform … continue reading

Software engineering leaders need to foster collaboration with site reliability engineers (SRE) in order to scale unplanned work and improve customer experience. Software engineering teams tend to focus on releasing new product features quickly, which causes them to not always prioritize the reliability of new features. Gartner predicts that by 2027, 75% of enterprises will … continue reading

Although the roles of the SRE and site platform engineer share some similarities and are at times conflated, they’re still distinct. Platform engineers are responsible for designing, developing and maintaining the underlying platform that the application runs on including the infrastructure, operating systems, databases and other components that enable the application to function. SREs, on … continue reading

There’s been an explosion of interest in SRE over the last 18 months and a lot of this has been from companies that are looking at scaling their DevOps or DevSecOps initiatives to look at the reliability concerns of their customers. Vendors are recognizing this and a lot of general software interfaces (GSIs) and Managed … continue reading
Gremlin has added Automatic Service Discovery to its chaos engineering platform in an effort to help companies improve resilience and reduce downtime by identifying the various services running across distributed systems. “The rise in popularity of microservices necessitate services functioning as first-class citizens. The infrastructure layer is becoming more abstract and engineers are increasingly thinking … continue reading

Qt announced that it will acquire froglogic GmbH, a major provider of quality assurance tools, to bring froglogic’s test automation tools into the Qt product portfolio. “As The Qt Company continues its growth, the acquisition of froglogic is an important milestone in broadening Qt’s best-in-class software development tools and building in automated testing and code … continue reading

A new report revealed those who have successfully implemented chaos engineering have 99.9% or higher availability and greatly improved their mean time to resolution (MTTR). Gremlin’s inaugural 2021 State of Chaos Engineering report found 23% of teams who frequently run chaos engineering projects had a MTTR of under 1 hour, and 60% under 12 hours. … continue reading

GitLab announced a new collaboration with Google Cloud to offer native integration into Google Kubernetes Engine (GKE). This new integration aligns with GitLab’s vision of Auto DevOps. Auto DevOps is GitLab’s way of automating DevOps and delivering ideas to production faster. It consists of a collection of build, test and deployment features. The new integration … continue reading
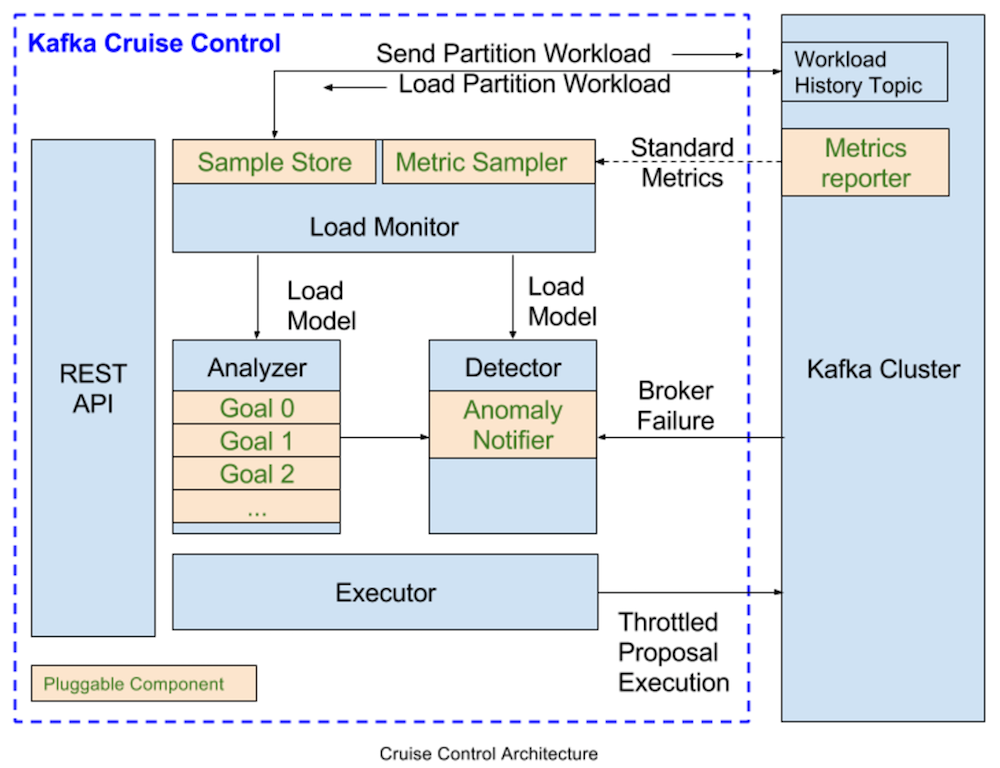
Although Apache Kafka is widely adopted, there are still operational challenges that teams run into when they try to run Kafka at scale. In order to restore balance to Kafka clusters, LinkedIn open sourced and developed Cruise Control, its general-purpose system that continuously monitors clusters and automatically adjusts the resources needed to meet pre-defined performance … continue reading

To ensure websites and applications deliver consistently excellent speed and availability, some organizations are adopting Google’s Site Reliability Engineering (SRE) model. In this model, a Site Reliability Engineer (SRE) – usually someone with both development and IT Ops experience – institutes clear-cut metrics to determine when a website or application is production-ready from a user … continue reading