
Fifteen years ago, the Hadoop data management platform was created. This kicked off a land rush of companies looking to plant their flags in the market and open-source projects began to spring up to extend what the platform was designed to do. As often happens with technology, it ages, and newer things emerge that either … continue reading

Earlier this month, data companies Cloudera and Hortonworks announced that they would be entering into a merger. Both companies were leaders in the big data space. The companies stated that they hoped the merger will enable them to become a next-generation data platform together. Cloudera was originally co-founded in 2008 with talent from Google, Facebook, … continue reading
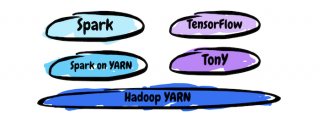
Unsatisfied with the available solutions for connecting the analytics-generating power of their TensorFlow machine learning implementations with the scalable data computation and storage capabilities of their Apache Hadoop clusters, developers at LinkedIn decided that they’d take matters into their own hands with the development of this week’s highlighted project, TonY. “TonY stands for TensorFlow on … continue reading
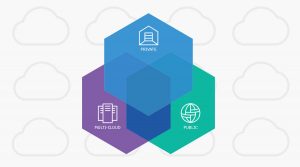
As companies accumulate data, they need new ways to store it, manage it, innovate off it, and scale services based on it. Earlier this year, IBM announced the IBM Cloud Private (ICP) for Data solution, and today the company is expanding it to provide new ways to uncover hidden insights from data. The company has … continue reading

The Apache HAWQ project is graduating from incubation to become a top-level project within the Apache Software Foundation this week. Apache HAWQ is a enterprise SQL-on-Hadoop query engine and analytics database that first entered the foundation’s incubation phase in September of 2015. “We are very excited to see Apache HAWQ graduate as a Top-Level Project … continue reading

Databases comprise one of the largest and most foundational segments of the IT landscape—in some cases, comprising over 50 percent of the cost of the total application stack. The size and prominence of this segment continues to expand unfettered. Recent estimates from Gartner peg the database market at $36.4 billion, having grown 8.6 percent in … continue reading

The term Big Data has been bandied about since the 1990s. It was meant to reflect the explosion of data – structured and unstructured — with which organizations are being deluged. They face issues that include the volume of data and the need to capture, store and retrieve, analyze and act upon that information. Technologies … continue reading

DRUD Tech announces ddev Community Open source development tool suppliers DRUD Tech have announced the release of ddev Community, a tool designed to streamline some of the backend aspects of website development. “Web development teams are all-too-familiar with the hours lost due to slow setup, task-switching between projects and lack of tooling consistency, whether it’s … continue reading

Today, data is fast-moving, very distributed, and is no longer sitting in one relational database. Data scientists, developers, and business analysts want to tap into data analytics on their own, so teams are turning to self-service data platforms like Dremio to eliminate the need for traditional Big Data systems and infrastructure. Dremio announced today that … continue reading
MicroStrategy is giving its users critical capabilities across enterprise analytics, so they can tap into business opportunities across one enterprise platform. The company today announced the availability of MicroStrategy 10.8, giving users enterprise analytics, mobility and IoT features, and making it easier to leverage machine learning. The new release includes the R and R Integration … continue reading

Google is making it easier to experiment with deep learning technologies with the release of Tensor2Tensor (T2T). T2T is an open source system for training deep learning mobiles with TensorFlow, Google’s software library for machine intelligence. With T2T, users can create models for apps like translation, parsing, image captioning and more. T2T includes a library … continue reading
Confluent shared its second annual Apache Kafka report this week, which demonstrates a surge in the use of Kafka. The survey also reveals that companies are implementing Kafka for “more accurate and faster decision making, reduced operating costs, improved customer experiences, and reduced risks,” according to the survey. “The results from this year’s Apache Kafka … continue reading