
At what stage is your Hadoop deployment? Is it still in the planning stages, in the lab, in development, in production or already making you money? Or is it still hiding under your desk? Let us know, and feel free to expand on your answer in the Comments section of this article! Where is your … continue reading

Databricks has announced the general availability of its cloud-hosted data platform, formerly known as Databricks Cloud. Less than a week after announcing the release of Apache Spark 1.4, Databricks debuted its cloud platform at Spark Summit, which has support for R-language notebooks; version-control and source-code change tracking from within Databricks; private notebook permissions management; and … continue reading

Data application infrastructure provider Concurrent has announced general availability of Cascading 3.0. The latest version of the enterprise Hadoop application development and deployment platform improves portability across programming languages such as Java, Scala and SQL, and across Hadoop distributions such as Cloudera, Hortonworks, MapR. And it now has native support for compute fabrics like Apache … continue reading

MapR announced the release of MapR 5.0, along with new auto-provisioning templates for data lake deployment, interactive SQL data exploration, and operational analytics at Hadoop Summit. Version 5.0 of the MapR Hadoop distribution adds a new Views feature for the newly released Apache Drill 1.1 for agile data governance, and granular access controls for better … continue reading

Ted Dunning, the newly appointed vice president of the Apache Incubator, is a Big Data scientist in a world of coders. Currently the chief application architect at Hadoop distribution company MapR, the longtime Apache Software Foundation contributor and project mentor took over as the ASF’s vice president of incubation in April. Tasked with keeping Apache … continue reading

The Apache Software Foundation has announced the release of Apache Drill 1.0. Drill is a schema-free SQL query engine for Hadoop, NoSQL and cloud storage that uses columnar execution, data-driven query compilation, and the JSON document model to store data in various formats for Big Data analytics and BI. Drill was upgraded to a Top-Level … continue reading

Google has announced Preemptible Virtual Machines, a new beta cloud technology for Google Compute Engine. Preemptible VMs are cloud instances that can be shut down at any time for short-term storage capacity at a low fixed cost. Google recommended them for distributed, fault-tolerant workloads that don’t require continuous availability of any single instance. The temporary … continue reading

Microsoft has announced the release of its Windows 10 Technical Preview for phones Build 10080. The release adds improvements and support for additional phones Windows Insiders have been requesting, according to the company. New phone support includes the Lumia 930/Lumia Icon, Lumia 640 and 640 XL, and the HTC One (M8). Additions to the build … continue reading
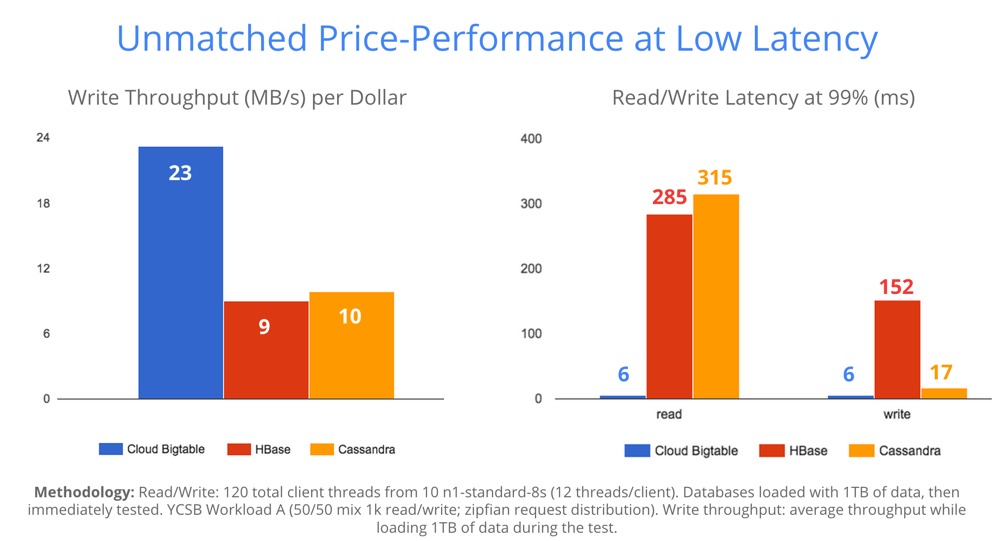
Google has launched Cloud Bigtable, a scalable, fully managed NoSQL database service available through the open-source Apache HBase API. Google Cloud Bigtable is an enterprise-focused NoSQL service for high-volume data ingestion, analytics and data-heavy serving workloads. The service includes a natively integrated open-source interface for Hadoop imported to existing HBase clusters along with replicated storage … continue reading
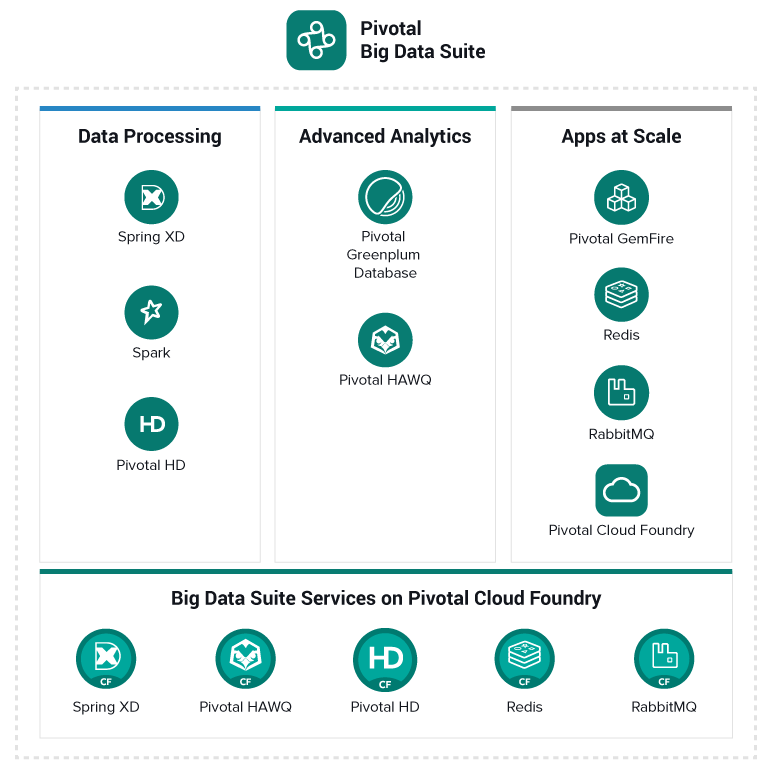
Pivotal has announced a revamped Big Data suite, featuring a new version of its Greenplum analytics database, along with the first version of its Pivotal HD Hadoop distribution aligned with the Open Data Platform core. At the EMC World conference in Las Vegas, the company rolled out its new release of Pivotal HD, which updates … continue reading

The Apache Software Foundation has announced Apache Parquet as a Top-Level Project. Apache Parquet, a columnar Hadoop storage format, is used across Big Data processing frameworks, data models and query engines from MapReduce and Apache Spark to Apache Hive, Impala and others. Parquet’s ascension to a Top-Level Project signifies the health and maturity of the … continue reading

Apache Spark stole the show at the Big Data TechCon in Boston this week. Thanks to a keynote address from Spark’s creator, and a number of tutorials focused on the project, attendees had plenty of Spark information on hand to learn at the event. While Spark was not the only Big Data topic being discussed … continue reading