LinkedIn wants to address bias in large-scale AI apps. The company introduced the LinkedIn Fairness Toolkit (LiFT) and shared the methodology it developed to detect and monitor bias in AI-driven products.
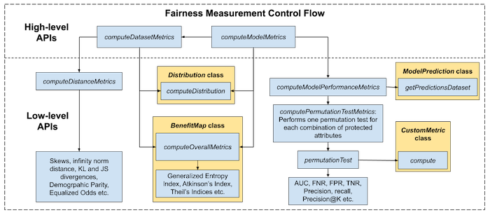
LiFT is a Scala/Spark library that enables the measurement of fairness, according to a multitude of fairness definitions, in large-scale machine learning workflows. It has broad utility for organizations who wish to conduct regular analyses of the fairness of their own models and data, according to the company.
“News headlines and academic research have emphasized that widespread societal injustice based on human biases can be reflected both in the data that is used to train AI models and the models themselves. Research has also shown that models affected by these societal biases can ultimately serve to reinforce those biases and perpetuate discrimination against certain groups,” AI and machine learning researchers at LinkedIn wrote in a blog post. “Although several open source libraries tackle such fairness-related problems, these either do not specifically address large-scale problems (and the inherent challenges that come with such scale) or they are tied to a specific cloud environment. To this end, we developed and are now open sourcing LiFT.”
The toolkit can be deployed in training and scoring workflows to measure biases in data, evaluate different fairness notions for ML models, and detect statistically significant differences in their performance across different subgroups, the researchers explained.
The library provides a basic driver program powered by a simple configuration, allowing quick and easy deployment in production workflows.
Users can access APIs at varying levels of granularity with the ability to extend key classes to enable custom computation.
The currently supported metrics include different kinds of distances between observed and expected probability distributions; traditional fairness metrics (e.g., demographic parity, equalized odds); and fairness measures that capture a notion of skew like Generalized Entropy Index, Theil’s Indices, and Atkinson’s Index.
The solution also introduced a metric-agnostic permutation testing framework that detects statistically significant differences in model performance – a testing methodology that will appear in KDD 2020.
Metrics available out-of-the box (like Precision, Recall, False Positive Rate (FPR), and Area Under the ROC Curve (AUC)) can be used with this test and with the CustomMetric class, users can define their own User Defined Functions to plug into this test. In order to accommodate the variety of metrics measured, LiFT makes use of a generic FairnessResult case class to capture results
“While a seemingly obvious choice for comparing groups of members, permutation tests can fail to provide accurate directional decisions regarding fairness. That is, when rejecting a test that two populations are identical, the practitioner cannot necessarily conclude that a model is performing better for one population compared with another,” the team wrote. “LiFT implements a modified version of permutation tests that is appropriate for assessing the fairness of a machine learning model across groups of users, allowing practitioners to draw meaningful conclusions.”
LinkedIn stated that the release of its toolkit is part of the company’s R&D efforts to avoid harmful bias in its platform, alongside Project Every Member and ‘diversity by design’ in LinkedIn Recruiter.




