The Apache Software Foundation (ASF) announced that Apache Gobblin, the open-source distributed Big Data integration framework, has reached top-level project status.
According to the foundation, achieving top-level status means that the project graduated from the Apache Incubator and has demonstrated that it’s community and products have been well-governed under the ASF’s meritocratic process and principles.
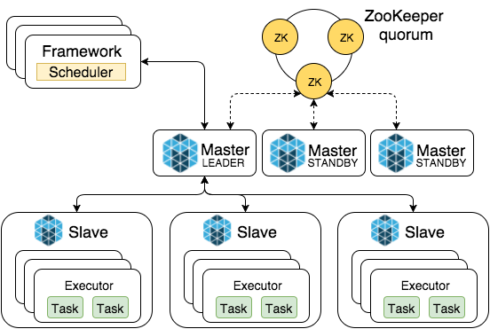
The project is dedicated for both streaming and batch data ecosystems and can integrate hundreds of terabytes and thousands of datasets per day by making it easier to ingest, replicate, and organize lifecycle management processes across different types of environments.
The project also simplifies data lake creation by supporting simple transformations and enabling organization within the lake through compaction, partitioning and deduplication.
Users can also benefit from the life cycle and compliance management of data within the lake that includes data retention and fine-grain data deletions, the ASF explained in a blog post.
“Apache Gobblin supports deployment models all the way from a single-process standalone application to thousands of containers running in cloud-native environments, ensuring that your data plane can scale with your company’s growth,” said Shirshanka Das, the founder and CTO at Acryl Data, a member of the Apache Gobblin Project Management Committee.
Gobblin originated at LinkedIn 2014, was open-sourced in 2015, and entered the Apache Incubator in 2017. Apache Gobblin software is released under the Apache License v2.0 and is overseen by a self-selected team of active contributors to the project.




