Just like some problems are too big for one person to solve, some tasks are too complex for a single AI agent. Instead, the best approach is to decompose problems into smaller, specialized units, where multiple agents work together as a team.
This is the foundation of multi-agent systems. Networks of agents, each with specific roles, collaborating to solve larger problems.
When building multi-agent systems, you need a way to coordinate how agents interact. If every agent talks to every other agent directly, things quickly become a tangled mess, making it hard to scale, and hard to debug. That’s where the orchestrator pattern comes in.
Instead of agents making ad-hoc decisions about where to send messages, a central orchestrator acts as the parent node, deciding which agent should handle a given task based on context. The orchestrator takes in messages, interprets them, and routes them to the right agent at the right time. This makes the system dynamic, adaptable, and scalable.
Think of it like a well-run dispatch center.
Instead of individual responders deciding where to go, a central system evaluates incoming information and directs it efficiently. This ensures that agents don’t duplicate work or operate in isolation, but can collaborate effectively without hardcoded dependencies.
In this article, I’ll walk through how to build an event-driven orchestrator for multi-agent systems using Apache Flink and Apache Kafka, leveraging Flink to interpret and route messages while using Kafka as the system’s short-term shared memory.
Why Event-Driven Agents?
At the core of any multi-agent system is how agents communicate.
Request/response models, while simple to conceptualize, tend to break down when systems need to evolve, adapt to new information, or operate in unpredictable environments. That’s why event-driven messaging, powered by technologies like Apache Kafka and Apache Flink, is typically the better model for enterprise applications.

Event-Driven Multi-Agent Communication
An event-driven architecture allows agents to communicate dynamically without rigid dependencies, making them more autonomous and resilient. Instead of hardcoding relationships, agents react to events, enabling greater flexibility, parallelism, and fault tolerance.
In the same way that event-driven architectures provide de-coupling for microservices and teams, they provide the same advantages when building a multi-agent system. An agent is essentially a stateful microservice with a brain, so many of the same patterns for building reliable distributed systems apply to agents as well.
Additionally, stream governance can verify message structure, preventing malformed data from disrupting the system. This is often missing in existing multi-agent frameworks today, making event-driven architectures even more compelling.
Orchestration: Coordinating Agentic Workflows
In complex systems, agents rarely work in isolation.
Real-world applications require multiple agents collaborating, handling distinct responsibilities while sharing context. This introduces challenges around task dependencies, failure recovery, and communication efficiency.
The orchestrator pattern solves this by introducing a lead agent, or orchestrator, that directs other agents in problem-solving. Instead of static workflows like traditional microservices, agents generate dynamic execution plans, breaking down tasks and adapting in real time.

The Orchestrator Agent Pattern
This flexibility, however, creates challenges:
-
Task Explosion – Agents can generate unbounded tasks, requiring resource management.
-
Monitoring & Recovery – Agents need a way to track progress, catch failures, and re-plan.
-
Scalability – The system must handle an increasing number of agent interactions without bottlenecks.
This is where event-driven architectures shine.
With a streaming backbone, agents can react to new data immediately, track dependencies efficiently, and recover from failures gracefully, all without centralized bottlenecks.
Agentic systems are fundamentally dynamic, stateful, and adaptive—meaning event-driven architectures are a natural fit.
In the rest of this article, I’ll break down a reference architecture for event-driven multi-agent systems, showing how to implement an orchestrator pattern using Apache Flink and Apache Kafka, powering real-time agent decision-making at scale.
Multi-Agent Orchestration with Flink
Building scalable multi-agent systems requires real-time decision-making and dynamic routing of messages between agents. This is where Apache Flink plays a crucial role.
Apache Flink is a stream processing engine designed to handle stateful computations on unbounded streams of data. Unlike batch processing frameworks, Flink can process events in real time, making it an ideal tool for orchestrating multi-agent interactions.
Revisiting the Orchestrator Pattern
As discussed earlier, multi-agent systems need an orchestrator to decide which agent should handle a given task. Instead of agents making ad-hoc decisions, the orchestrator ingests messages, interprets them using an LLM, and routes them to the right agent.
To support this orchestration pattern with Flink, Kafka is used as the messaging backbone and Flink is the processing engine:

Powering Multi-Agent Orchestration with Flink
-
Message Production:
-
Agents produce messages to a Kafka topic.
-
Each message contains the raw contextual data relevant to an agent.
-
-
Flink Processing & Routing:
-
A Flink job listens to new messages in Kafka.
-
The message is passed to an LLM, which determines the most appropriate agent to handle it.
-
The LLM’s decision is based on a structured Agent Definition, which includes:
-
Agent Name – Unique identifier for the agent.
-
Description – The agent’s primary function.
-
Input – Expected data format the agent processes enforced by a data contract.
-
Output – The result the agent generates.
-
-
-
Decision Output and Routing:
-
Once the LLM selects the appropriate agent, Flink publishes the message to an HTTP endpoint associated with the identified agent.
-
-
Agent Execution & Continuation:
-
The agent processes the message and writes updates back to the agent messages topic.
-
The Flink job detects these updates, reevaluates if additional processing is required, and continues routing messages until the agent workflow is complete.
-
Closing the Loop
This event-driven feedback loop allows multi-agent systems to function autonomously and efficiently, ensuring:
-
Real-time decision-making with no hardcoded workflows.
-
Scalable execution with decentralized agent interactions.
-
Seamless adaptability to new inputs and system changes.
In the next section, we’ll walk through an example implementation of this architecture, including Flink job definitions, Kafka topics, and LLM-based decision-making.
Building an Event-Driven Multi-Agent System: A Hands-On Implementation
In previous sections, we explored the orchestrator pattern and why event-driven architectures are essential for scaling multi-agent systems. Now, we’ll show how this architecture works by walking through a real-world use case: an AI-driven sales development representative (SDR) system that autonomously manages leads.

Event-Driven AI Based SDR using a Multi-Agent System
To implement this system, we utilize Confluent Cloud, a fully managed service for Apache Kafka and Flink.
The AI SDR Multi-Agent System
The system consists of multiple specialized agents that handle different stages of the lead qualification and engagement process. Each agent has a defined role and operates independently within an event-driven pipeline.
Agents in the AI SDR System
-
Lead Ingestion Agent: Captures raw lead data, enriches it with additional research, and generates a lead profile.
-
Lead Scoring Agent: Analyzes lead data to assign a priority score and determine the best engagement strategy.
-
Active Outreach Agent: Uses lead details and scores to generate personalized outreach messages.
-
Nurture Campaign Agent: Dynamically creates a sequence of emails based on where the lead originated and what their interest was.
-
Send Email Agent: Takes in emails and sets up the campaign to send them.
The agents have no explicit dependencies on each other. They simply produce and consume events independently.
How Orchestration Works in Flink SQL
To determine which agent should process an incoming message, the orchestrator uses external model inference in Flink. This model receives the message, evaluates its content, and assigns it to the correct agent based on predefined functions.
The Flink SQL statement to set up the model is shown below with an abbreviated version of the prompt used for performing the mapping operation.
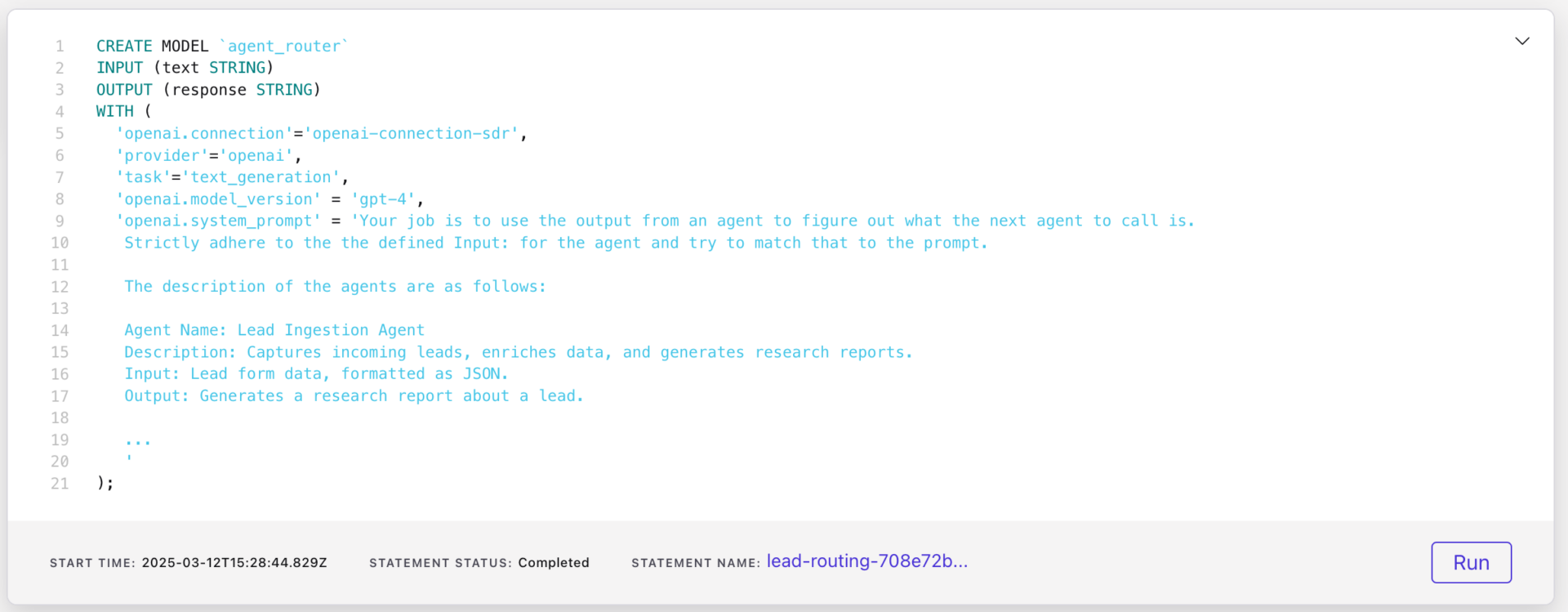
After creating the model, we create a Flink job that uses this model to process incoming messages and assign them to the correct agent:

This automatically routes messages to the appropriate agent, ensuring a seamless, intelligent workflow. Each agent processes its task and writes updates back to Kafka, allowing the next agent in the pipeline to take action.
Executing Outreach
In the demo application, leads are written from a website into MongoDB. A source connector for MongoDB sends the leads into an incoming leads topic, where they are copied into the agent messages topic.
This action kick starts the AI SDR automated process.
The query above shows that all decision making and evaluation is left to the orchestrator with no routing logic hard-coded. The LLM is reasoning on the best action to take based upon agent descriptions and the payloads routed through the agent messages topic. In this way, we’ve built an orchestrator with only a few lines of code with the heavy lifting done by the LLM.
Wrapping Up: The Future of Event-Driven Multi-Agent Systems
The AI SDR system we’ve explored demonstrates how event-driven architectures enable multi-agent systems to operate efficiently, making real-time decisions without rigid workflows. By leveraging Flink for message processing and routing and Kafka for short-term shared memory, we achieve a scalable, autonomous orchestration framework that allows agents to collaborate dynamically.
The key takeaway is that agents are essentially stateful microservices with a brain, and the same event-driven principles that scaled microservices apply to multi-agent systems. Instead of static, predefined workflows, we enable systems and teams to be de-coupled, adapt dynamically, reacting to new data as it arrives.
While this blog post focused on the orchestrator pattern, it’s important to note that other patterns can be supported as well. In some cases, more explicit dependencies between agents are necessary to ensure reliability, consistency, or domain-specific constraints. For example, certain workflows may require a strict sequence of agent execution to guarantee transactional integrity or regulatory compliance. The key is finding the right balance between flexibility and control depending on the application’s needs.
If you’re interested in building your own event-driven agent system, check out the GitHub repository for the full implementation, including Flink SQL examples and Kafka configurations.