Amazon is addressing artificial intelligence development challenges with a new end-to-end compiler solution. The NNVM compiler, developed by AWS and a team of researchers from the University of Washington’s Allen School of Computer Science & Engineering, is designed for deploying deep learning frameworks across a number of platforms and devices.
“You can choose among multiple artificial intelligence (AI) frameworks to develop AI algorithms. You also have a choice of a wide range of hardware to train and deploy AI models. The diversity of frameworks and hardware is crucial to maintaining the health of the AI ecosystem. This diversity, however, also introduces several challenges to AI developers,” Mu Li, a principal scientist for AWS AI, wrote in a post.
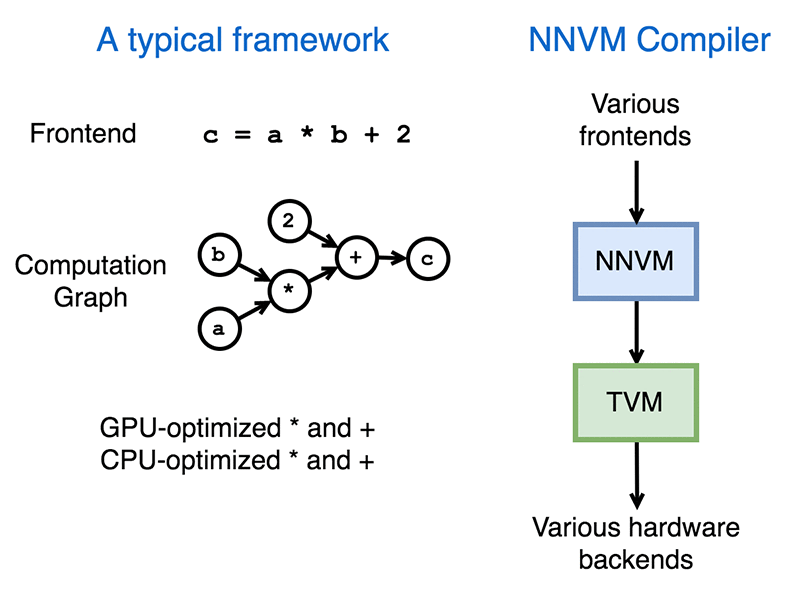
According to Amazon, there are three main challenges AI developers come across today: switching between AI frameworks, maintaining multiple backends, and supporting multiple AI frameworks. The NNVM compiler addresses this by compiling front-end workloads directly into hardware back-ends. “Today, AWS is excited to announce, together with the research team from UW, an end-to-end compiler based on the TVM stack that compiles workloads directly from various deep learning frontends into optimized machine codes,” Li wrote. The TVM stack, also developed by the team, is an intermediate representation stack designed to close the gap between deep learning frameworks and hardware backends.
“While deep learning is becoming indispensable for a range of platforms — from mobile phones and datacenter GPUs, to the Internet of Things and specialized accelerators — considerable engineering challenges remain in the deployment of those frameworks,” said Allen School Ph.D. student Tianqi Chen. “Our TVM framework made it possible for developers to quickly and easily deploy deep learning on a range of systems. With NNVM, we offer a solution that works across all frameworks, including MXNet and model exchange formats such as ONNX and CoreML, with significant performance improvements.”
The NNVM compiler is made up of two components from the TVM stack: NNVM for computation graphs and TVM for tensor operators, according to Amazon.
“NNVM provides a specification of the computation graph and operator with graph optimization routines, and operators are implemented and optimized for target hardware by using TVM. We demonstrated that with minimal effort this compiler can match and even outperform state-of-the-art performance on two radically different hardware: ARM CPU and Nvidia GPUs,” Li wrote. “We hope the NNVM compiler can greatly simplify the design of new AI frontend frameworks and backend hardware, and help provide consistent results across various frontends and backends to users.”