Facebook has been working on its own natural language processing (NLP) framework for overcoming rapid experimentation and large-scale deployment challenges. PyText is a library based on the company’s open-source deep learning framework PyTorch.
In an effort to help developers build and deploy NLP systems, the company has decided to also open source the PyText framework as well as share its pretrained models and tutorials.
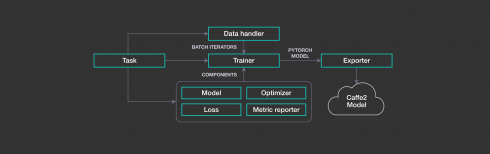
According to the company, with PyText it has been able to achieve faster experimentation, tackle text processing and vocabulary management at scale, and harness the PyTorch ecosystem for prebuilt models and tools.
“At Facebook, we’ve used this framework to take NLP models from idea to full implementation in just days, instead of weeks or months, and to deploy complex models that rely on multitask learning. At Facebook today, PyText is used for more than a billion daily predictions, demonstrating that it can operate at production scale and still meet stringent latency requirements,” the company wrote in a blog post.
The company explained that traditionally researchers and engineers have to tradeoff between frameworks built for experiments and frameworks built for production. “This is particularly true for NLP systems, which can require creating, training, and testing dozens of models, and which use an inherently dynamic structure. Research-oriented frameworks can provide an easy, eager-execution interface that speeds the process of writing advanced and dynamic models, but they also suffer from increased latency and memory use in production,” Facebook explained.
With the power of PyTorch 1.0, which addressed research and production obstacles with a single unified framework, PyText is able to bring PyTorch’s 1.0 features into natural language processing. Features include the ability to share models across different organizations within the AI community, prebuilt models of common NLP tasks such as text classification and language modeling, and contextual models to improve conversational understanding.
Facebook plans to use the framework in its own solutions to provide powerful features, flag policy-violating posts, perform translations, and improve products, it explained.
Going forward, the company plans to tackle end-to-end workflows for on-device models and provide multilingual modeling as well as other modeling capabilities that provide the ability to debug and improve distributed training.
“PyText has been a collaborative effort across Facebook AI, including researchers and engineers focused on NLP and conversational AI, and we look forward to working together to enhance its capabilities,” the company wrote.



