Microservices are in the spotlight, as infrastructure building blocks, because they offer decoupling of services, data store autonomy, miniaturized development, testing set up, and other benefits that facilitate faster time to market for new applications or updates. The availability of containers and their orchestration tools has also contributed to the increase in microservices adoption. At its core, the rise of microservices is the rejection of the traditional architecture approach, in which a monolithic database is shared between services. Microservices, in contrast, embrace independent, autonomous, specialized data stores for each microservice.
An e-Commerce solution, for example, may employ the following services: application server; content cache; session store; product catalog; search and discovery; order processing; order fulfillment; analytics; and many more. Rather than use a large, single database to store all of the operational and transactional data, a modern e-Commerce solution may use a microservices architecture similar to the one depicted in Figure 1, in which each service has its own database.
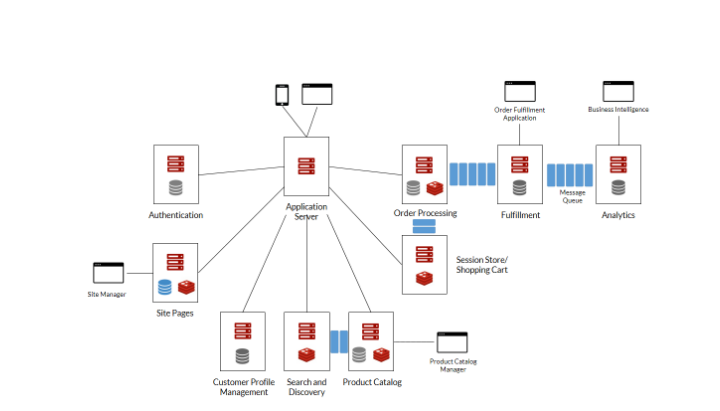
Figure 1. Microservices in a sample e-Commerce Solution
How to choose a data store for your microservice
One of the most important questions to answer while designing microservices is, “How does one choose the right data store?”
The first step when choosing the ideal data store is to determine the nature of your microservice’s data. The data can be broadly classified into the following categories:
- Ephemeral data: A cache server is a good example of an ephemeral data store. It is a temporary data store whose purpose is to improve the user experience by serving information in real time. The microservice is typically tuned for high performance and the operations are read intensive. The store has no durability requirements as it does not store the master copy of the data, but it still has to be highly available because failures could cause user experience issues and subsequently, lost revenue. Separately, failures can also cause “cache stampede” issues, where much slower databases crawl because they cannot handle the high frequency accesses, and this in turn can result in incidents and tickets that could have been completely avoided.
- Transient data: Data such as logs, messages and signals usually arrive in high volume and velocity. Data ingest services typically process this information before passing it to the appropriate destination. Such data stores need to support high-speed writes. Additional built-in capabilities to support time-series data and JSON are a plus. The durability requirements of transient data are higher than that of ephemeral data, but not as high as transactional data.
- Operational data: Information gathered from user sessions, such as user profiles, shopping cart contents, etc., are considered operational data. The microservice offers better user experience with real-time feedback. Even though the data stored in the database is not a permanent proof of record, the architecture must make its best effort to retain the data for business continuity. For operational data, the data durability, consistency and availability requirements are high. Often, operational data is organized in a particular data model such as JSON, graph, relational, key-value, etc.
- Transactional data: Data gathered from transactions such as payment processing and order processing must be stored as a permanent record in a database that supports strong ACID controls.
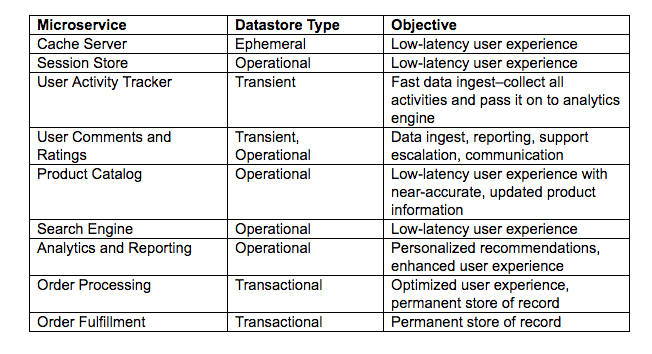
In the e-Commerce application shown in Figure 1, we can classify the microservices and their respective data stores as shown in the table below:
Tunability for consistency and durability
In order to optimize your microservice for performance and data durability requirements, it’s important to confirm that your selected database offers the appropriate tunability features for the data categories that you’ve identified. For high performance, a pure in-memory database is an ideal choice. For durability, data replication along with persistence on disk or flash storage is the best solution. For example, the cache server in our e-Commerce example must be optimized for low-latency, high-speed read operations. Based on the nature of the data, the database need not be burdened with durability options. On the other hand, the order fulfillment microservice focuses on keeping the data clean and consistent.
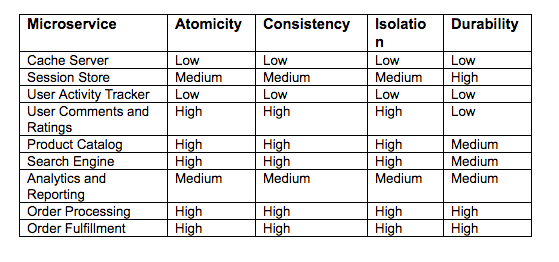
The table below shows how the data store for each microservice should be configured and tuned based on its requirements for atomicity, consistency, isolation and durability.
Lastly, it is also important to evaluate the deployment and orchestration options available with the database in order to ensure that all microservices are deployed and managed in a homogenous environment. Some key criteria to look for include:
- Availability as a container: Since microservices are mostly deployed as containers managed by orchestration tools, there is great operational efficiency to be gained when also using databases as containers.
- Cloud/on-premises options: Is the database available on the cloud or on-premises, where the microservice is deployed? A database that’s available for both deployment options offers greater flexibility.
- Vendor lock-in: Organizations sometimes switch orchestration tools, so it’s helpful to make sure the database supports all popular orchestration tools.