Recently, there’s been a new change proposal for Cassandra indexing that attempts to reduce the tradeoff between usability and stability: Making the WHERE clause much more interesting and useful for end-users. This new method is called Storage-Attached Indexing (SAI). It’s not the flashiest name, but what do you expect? Engineers aren’t known for naming things, but cool technology is never a joke. SAI has captured the attention of the Cassandra community, but why? Indexing data is not a new concept in the database world.
How we index our data can change over time based on the desired use cases and deployment models. Cassandra was built combining aspects of Dynamo and Big Table to reduce the complexity of read and write overhead by keeping things simple. The complexity of Cassandra has been mostly reserved to its distributed nature and as a result, created a tradeoff for developers. If you want the incredible scale of Cassandra, you have to spend the time learning how to data model. Database indexes are meant to enhance your data model and make your queries more efficient. For Cassandra, they have existed in some form since the early days of the project. The unfortunate reality is that they haven’t matched well with user requirements. Any use of indexing comes with a long list of tradeoffs and warnings to the point that they are mostly avoided and for some, just a hard no. As a result, users have learned how to data model with basic queries to get the best performance.
Those days may be getting behind us and features like SAI are helping us get there.
Secondary indexes in distributed databases
Not all indexes are created equal. Primary indexes are also known as the unique key, or in Cassandra vocabulary, partition key. As a primary access method on the database, Cassandra utilizes the partition key to identify the node holding the data then the data file that stores the partition of data. Primary index reads in Cassandra are fairly simple but beyond the scope of this article. You can read more about them here.
Secondary indexes create a completely different and unique challenge in a distributed database. Let’s look at an example table to make a few points:
CREATE TABLE users (
id long,
firstName text,
lastName text,
country text,
created timestamp,
PRIMARY KEY (id)
);
A primary index lookup would be pretty simple like this:
SELECT firstName, lastName FROM users WHERE id = 100;
What if I wanted to find everyone in France? As someone familiar with SQL, you would expect this query to work:
SELECT firstName, lastName FROM users WHERE country = ‘FR’;
Without creating a secondary index in Cassandra, this query will fail. The fundamental access pattern in Cassandra is by partition key. In a non-distributed database like a traditional RDBMS, every column of the table is easily visible to the system. You can still access the column even if there is no index since they all exist in the same system and data files. Indexes in this case help reduce query time by making the lookup more efficient.
In a distributed system like Cassandra, the column values are on each data node and must be included in the query plan. This sets up what we call the “Scatter-Gather” scenario where a query is sent to every node, data is collected, merged, and returned to the user. Even though this operation can be done over multiple nodes at once, the latency management is down to how fast the node can find the column value.
Quick review of Cassandra data writes
You may be thinking that adding indexes is about reading data, which is certainly the end goal. However, when building a database the technical challenges on indexing are biased at the point where data is written. Accepting the data at the fastest speed while formatting the indexes in the most optimal form for reads is a huge challenge. It’s worth doing a quick review of how data is written in a Cassanda database at the individual node level. Refer to the following diagram as I explain how it works.
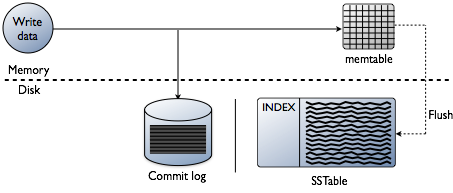
When data is presented to a node, which we call a mutation, the write path for Cassandra is very simple and optimized for that operation. This is also true for many other databases based on Log-Structured Merge(LSM) trees.
- Validate data is the correct format. Type check against the schema.
- Write data into the tail of a commit log. No seeks, just the next spot on the file pointer.
- Write data into a memtable, which is just a hashmap of the schema in memory.
Done! The mutation is acknowledged when those things happen. I love how simple this is compared to other databases that require a lock and seek to perform a write.
Later, as the memtables fill physical memory, a flush process writes out segments in a single pass on disk to a file called an SSTable (Sorted Strings Table). The accompanying commit log is deleted now that the persistence has moved to the SSTable. This process keeps repeating as data is written to the node.
Important detail: SSTables are immutable. Once they are written they never get updated, just replaced. Eventually, as more data is written, a background process called compaction merges and sorts sstables into new ones which are also immutable. There are a lot of compaction schemes, but fundamentally, they all perform this function.
You now have enough basic foundation on Cassandra so we can get sufficiently nerdy with indexes. Any further depth of information is left as an exercise for the reader.
Issues with previous indexing
Cassandra has had two previous secondary indexing implementations. Storage Attached Secondary Indexing(SASI) and Secondary Indexes, which we refer to as 2i. Again, my point about engineers not being flashy with names holds up here. Secondary indexes have been a part of Cassandra from the beginning, but the implementations have made them troublesome for end-users with their long list of tradeoffs. The two main concerns we have constantly dealt with as a project are write amplification and index size on disk. As a result, they can be frustratingly tempting to new users only to have them fail later in the deployment. Let’s look at each.
Secondary Indexes (2i) — This original work in the project started out as a convenience feature for early Thrift data models. Later, as Cassandra Query Language replaced Thrift as the preferred query method for Cassandra, 2i functionality was retained with the “CREATE INDEX” syntax. If you had come from SQL, this was a really easy way to learn the law of unintended consequences. Just like in SQL indexing, the more you add the more you affect write performance. However, with Cassandra, this triggered the larger issue with write-amplification. Referring to the write path above, Secondary Indexes added a new step into the path. When a mutation on an indexed column occurs, an indexing operation is triggered that re-indexes data in a separate index file. More indexes on a table can dramatically increase disk activity in a single row write operation. When a node is taking a high amount of mutations, the result can be saturated disk activity which can make the individual nodes unstable, giving 2i the deserved guidance of “use sparingly.” Index size is fairly linear in this implementation but with re-indexing, the amount of disk space needed can be hard to plan for in an active cluster.
Storage Attached Secondary Indexing (SASI) — SASI was originally designed by a small team at Apple to solve a specific query problem and not the general problem of secondary indexes. To be fair to that team, it got away from them in a use case that it was never designed to solve. Welcome to open source everyone. The two query types that SASI was designed to address:
- Finding rows based on partial data matching. Wildcard, or LIKE queries.
- Range queries on sparse data, specifically timestamps. How many records fit in a time range type queries.
It did both of those operations quite well and it also addressed the issue of write amplification with legacy 2i. As mutations are presented to a Cassandra node, the data is indexed in-memory during the initial write, much like how memtables are used. No disk activity is required on a permutation. A huge improvement on clusters with a lot of write activity. When memtables are flushed to sstables, the corresponding index for the data is flushed. Every index file written is immutable and attached to the sstable, hence the name Storage Attached. When compaction occurs, data is reindexed and written to a new file as new sstables are created. From a disk activity standpoint, this was a major improvement. The downside of SASI was primarily in the size of the indexes created. The on-disk index format caused an enormous amount of disk space used for each column indexed. This makes them very difficult to manage for operators. In addition, SASI was marked as experimental and not much has happened with regards to feature improvement. Many bugs have been found over time with expensive fixes that have brought on the discussion of whether SASI should be removed altogether. If you need the deepest dive on this feature, Duy Hai Doan did an amazing job of breaking down how SASI works.
What makes SAI better
The first, best answer to that question is that SAI is evolutionary in nature. Engineers at DataStax realized that the core architecture of Secondary Indexing needed to be addressed from the ground up but with solid lessons that have been learned from previous implementations. Addressing the issues of write-amplification and index file size while creating a path for better query enhancements in Cassandra has been the primary mission. How does SAI address both of these topics?
Write amplification — As we learned from SASI, in-memory indexing and flushing indexes with SSTables was the right way to keep in line with how the Cassandra write-path works, while adding new functionality. With SAI, when the mutation is acknowledged, meaning fully committed, the data is indexed. With optimizations and a lot of testing, the impact on write performance has vastly improved. You should see better than a 40% increase in throughput and over 200% better write latencies over 2i. That being said, you should still plan on an increase of 2x latency and throughput on indexed tables compared to non-indexed tables. To quote Duy Hai Doan, “There is no magic,” just good engineering.
Index size — This is the most dramatic improvement and arguably where most work has been done. If you follow the world of database internals, you know that data storage is still a lively field filled with continuously evolving improvements. SAI uses two different types of indexing schemes based on the data type.
- Text – Inverted indexes are created with terms broken into a dictionary. The biggest improvement is from the use of Trie based indexing which offers much better compression which means smaller index sizes.
- Numeric – Utilizing a data structure called block kd-trees, taken from Lucene, which offers excellent range query performance. A separate row ID list is maintained to optimize for token order queries.
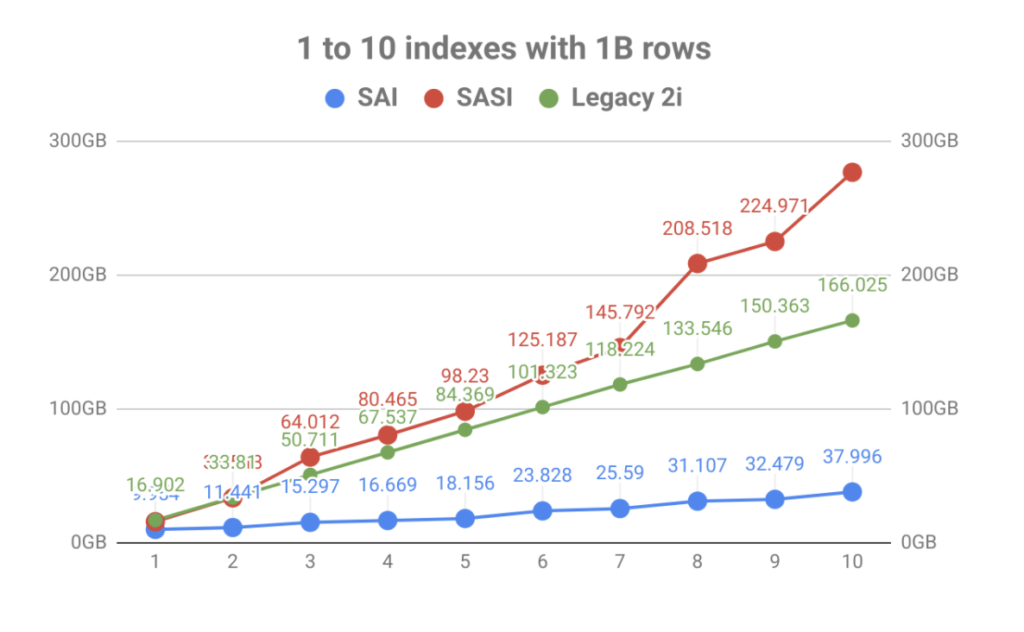
With a strong emphasis on index storage, the result was a massive improvement in the volume vs the number of table indexes. As you can see in the graph below, the fast indexing brought by SASI was quickly eclipsed by the explosion of disk usage. Not only does it make operational planning a pain, but the index files had to be read during compaction events which could saturate disks leading to node performance issues.
Outside of write amplification and index size, the internal architecture of SAI allows for further expansion and added functionality in the future. This is in line with project goals to be more modular in future builds. Take a look at some of the other CEPs that are pending and you can see that this is only the beginning.
Where does SAI go from here?
DataStax has offered SAI to the Apache Cassandra project through the Cassandra Enhancement Process as CEP-7. The discussion is on now for inclusion in the 4.x branch of Cassandra.
If you want to try this now before it’s a part of the Apache Cassandra project, we have a couple places for you to go. For operators or people who like a little more technical hands-on, you can download the latest DataStax Enterprise 6.8. If you are a developer, SAI is now enabled in DataStax Astra, our Cassandra as a Service. You can create a free-forever tier to play around with syntax and new where clause functionality. With that, learn how to use this feature by going to the Cassandra Indexing Skills Page and included documentation.




