
In the current age of digital transformation, data has emerged as the cornerstone of business operations. The rapid accumulation of information brings opportunities and challenges for organizations seeking to harness data’s potential. As evidenced by recent statistics from the Reveal survey, data-driven strategies are on the rise, with eight in ten software developers (80.8%) incorporating … continue reading

The Apache Kudu Project is, as of today, a top-level project within the open-source technology foundation. Originally contributed by Cloudera, the project is an effort to build a highly efficient and fast analytics platform for quickly moving data, such as streams. Kudu, in practice, is actually a columnar storage manager for Hadoop. The system is … continue reading
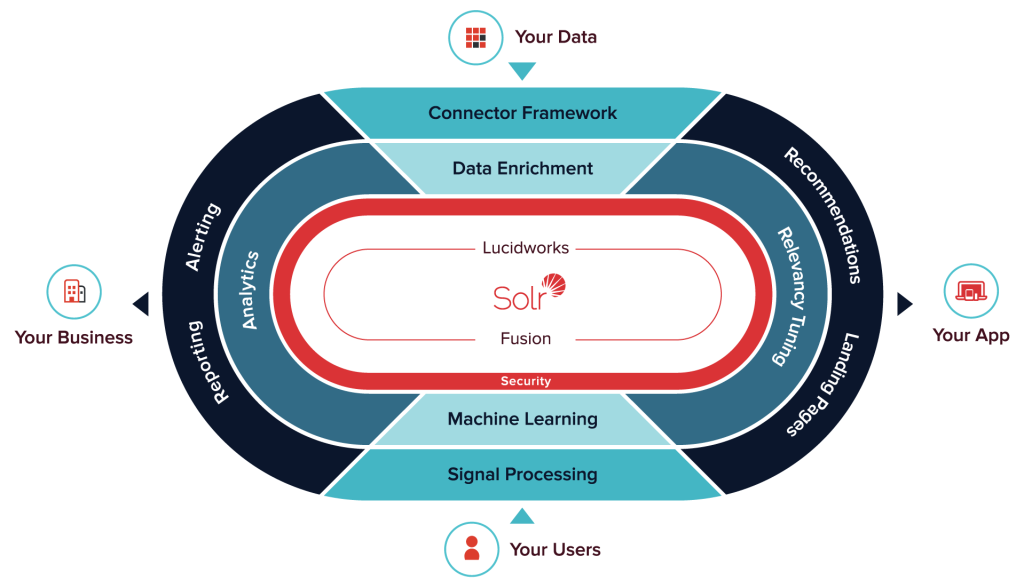
Lucidworks has released version 2.0 of Fusion, its enterprise Big Data search product built on Apache Solr storage architecture, with Apache Spark integration and a revamped SiLK dashboard. Fusion 2.0’s Spark integration within its data-processing layer enables real-time analytics within the enterprise search platform, adding Spark to the Solr architecture to accelerate data retrieval and … continue reading

I once wrote a parking sticker application for an East Coast university. If you had a faculty, staff, student or visitor sticker for the campus, it was processed using my green-screen application, which went online in 1983. The university used the mainframe program with minimal changes for about a decade, until a new client/server parking … continue reading

Data on today’s storage media may be inaccessible in the future as new technology emerges. What can be done about this? … continue reading
How will we, as a society, deal with deprecated file formats and storage media and the data that they contain? … continue reading