
Data capture provides a better way to make informed decisions, but only when an organization truly taps into the value of that data. We capture data on and around everything, meaning information availability isn’t the issue. The challenges now are: How can we get more value from that data? How can we make sure we’re … continue reading
MongoDB yesterday added new capabilities to its MongoDB Atlas developer data platform, including generative AI, stream processing and more. The details were announced at the company’s developer conference in New York City. MongoDB Atlas Vector Search now uses generative AI to create highly relevant data retrieval and personalization into applications for improved customer experiences, the … continue reading

Until recently, data science was a mostly academic pursuit and the subject of papers rather than practice. Over time, data science became an applied science with data scientists being paired with data engineers to develop production systems. We are now entering a new phase where much of the work being performed by data scientists (hyperparameter … continue reading
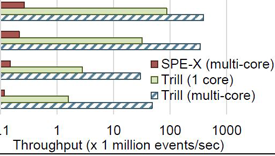
Earlier this week, Microsoft announced the open-source release of its streaming data analysis and query tool Trill, a single-node engine library that can be incorporated into .NET applications to process complex queries in real-time or offline data sets. In a blog post about the release, principal software engineer James Terwilliger explained that Trill has been … continue reading

Open-source software foundation Apache released version 1.0.0 of its Kafka distributed data streaming platform today, with the first full version number indicating Apache’s confidence that Kafka is ready for major professional use. “Apache Kafka is playing a bigger role as companies are moving to real-time streaming and embracing stream processing,” Jun Rao, vice president of … continue reading

Hazelcast today released the first version of Hazelcast Jet, a distributed processing engine for Big Data streams. Jet integrates with the Hazelcast in-memory data grid to process data in parallel across nodes in near real time. Hazelcast Jet uses directed acyclic graphs to model relationships between tasks in the data-processing pipeline. The system is built … continue reading

The Apache Foundation this morning announced the promotion of Apache Beam to the top level. That’s good news for the many contributors and users of this unified programming model, which allows them to write batch and streaming jobs at the same time, and to run the resulting artifact on various execution engines. Within the Hadoop … continue reading
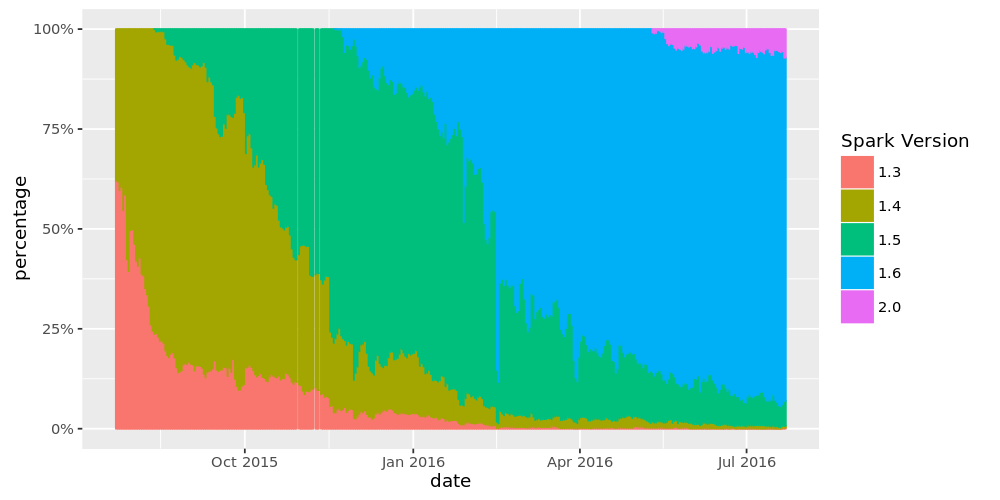
Databricks has announced the general availability of Apache Spark 2.0 on its platform, building on what the Databricks community has learned and focusing on three themes: ease of use, more speed, and more intelligence, according to the company. From the preview release of Apache Spark 2.0, Databricks said that 10% of its clusters were already … continue reading

Confluent this week introduced its first commercial product, Confluent Control Center, as part of the newly released Confluent Platform 3.0 and Apache Kafka 0.10.0. The combined package is aimed at operationalizing Kafka-based streaming applications and near real-time data processing efforts. Neha Narkhede, cofounder and CTO of Confluent (and one of the creators of Kafka), said, … continue reading

When you’re watching the Oakland Athletics beat up on the Anaheim Angels on the MLB.tv streaming service, you’re probably not thinking about the software involved in that equation. But it’s the software that has taken 15 years of continual evolution to get to the point where, nowadays, baseball’s premium subscription service isn’t just a nice … continue reading

While many in the Big Data space are talking about stream processing, MapR today announced the availability of Streams, a new product in its Hadoop stack that can be used to stream events across clusters distributed around the world. The new product offers a publish-and-subscribe model for event-driven data access and decision-making. While MapR Streams … continue reading
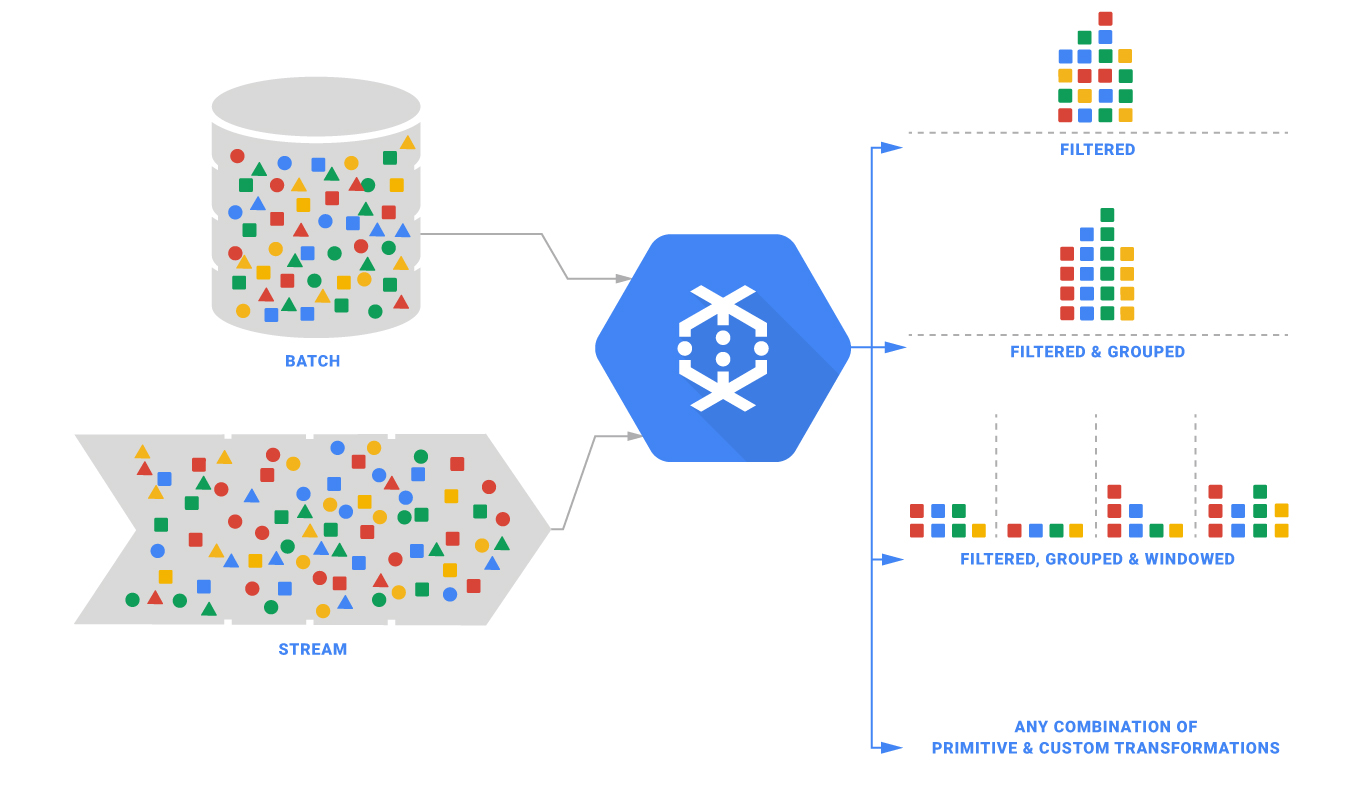
Google this morning removed the beta label from Google Cloud Dataflow. The company also introduced Google Cloud Pub/Sub, as well as integrations between these services and the Google BigQuery service. Together, developers can use these services to provide analytics, stream processing and batch processing applications within the same infrastructure. Cloud Dataflow is built around the … continue reading