Google has proposed a new approach to natural language understanding architectures beyond a fixed-length context. Transformer-XL aims to make long-range dependence more practical in neural networks by using attention models.
According to the company, long-range dependence is the contextual ability humans have to parse information that depends on something they’d read much earlier in a document or set of data. Google AI developers Zhilin Yang and Quoc Le explained that the Transformer-XL architecture will enable natural language understanding that surpasses the present methods of gating-based RNNs and use of the gradient clipping technique, as well as traditional Transformers, which connect only fixed-length segments of data and often ignore sentence boundaries and can’t model dependencies past that fixed length.
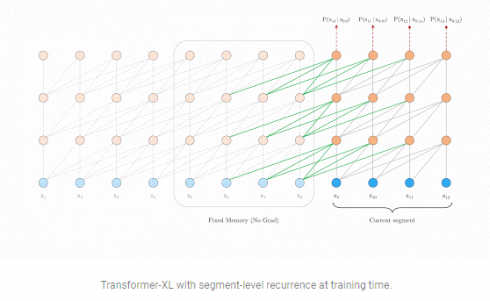
Yang and Le wrote in a developer blog that Transformer-XL addresses those shortcomings with two methods, segment-level recurrence and relative positional encoding.
“During training, the representations computed for the previous segment are fixed and cached to be reused as an extended context when the model processes the next new segment,” Yang and Le wrote of their segment-level recurrence mechanism. “This additional connection increases the largest possible dependency length by N times, where N is the depth of the network, because contextual information is now able to flow across segment boundaries. Moreover, this recurrence mechanism also resolves the context fragmentation issue, providing necessary context for tokens in the front of a new segment,” the AI developers wrote.
But Yang and Le note that without the second part of the equation, their relative positional encoding scheme, the expanding segments of contextual information wouldn’t be coherent.
“For example, consider an old segment with contextual positions [0, 1, 2, 3],” the pair wrote. “When a new segment is processed, we have positions [0, 1, 2, 3, 0, 1, 2, 3] for the two segments combined, where the semantics of each position id is incoherent through out the sequence.”
By making the transformations, the context between two segments, learnable, rather than the embeddings as in prior schemes, the connections become “more generalizable to longer sequences at test time.”
This method sees a significant speed increase compared to prior methods of incorporating long-range dependence in neural networks, the researchers wrote, with dependencies reaching lengths 80 percent greater than in RNNs and 450 percent greater than in “vanilla” Transformers. Transformer-XL is also greater than 1800x faster than vanilla Transformers “during evaluation on language modeling tasks, because no re-computation is needed.”



