Data orchestration provider Alluxio has announced the release of three new architectural components as part of its Structured Data Service. The new components include a new Presto connector, a new data catalog service, and a data transformation service.
According to the company, the Presto connector will allow administrators to easily integrate and configure Alluxio with Presto.
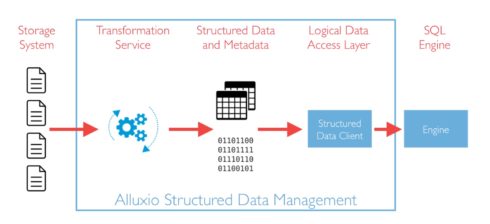
Its new Catalog Service will manage metadata of structured data, and will be responsible for all database, table, and schema information as well as location of stored data.
The transformation service will transform data into a compute-optimized representation, allowing for physical data independence. According to Steven Mih, CEO of Alluxio, this will enable up to five times improved query speed. “That turns into analysts being more efficient,” he said. “They can run five times more queries, data scientists can run their models five times better and faster, and that turns into business insights that help the business.”
“Alluxio now provides just-in-time data transform of data to be compute-optimized, independent of the storage format for OLAP engines, such as Presto and Apache Spark,” said Haoyuan Li, founder and CTO of Alluxio. “These schema-aware optimizations are made possible with the new Alluxio Catalog Service which abstracts the widely-used Apache Hive Metastore, so regardless of how the data was initially stored – CSV and text formatted files, for example – the data is now transformed into the generally recognized compute-optimized parquet format. Almost every organization has a surprising amount of data in CSV or other text formats and this removes the manual work to make that data more usable. A second type of transformation will coalesce many smaller files, enabling the data to be combined into fewer files, which is more efficient to process for SQL engines. And yet a third type of transformation is for sorting, enabling table columns to be sorted adding to the efficiency of queries, newly available in our Enterprise Edition. ”




