The 2021 State of DevOps report indicates that greater than 74% of organizations surveyed have Change Failure Rate (CFR) greater than 16% (the report provides a range from 16% to 30%). Of these, a significant proportion (> 35%) likely have CFRs exceeding 23%.
This means that while organizations seek to increase software change velocity (as measured by the other DORA metrics in the report), a significant number of deployments result in degraded service (or service outage) in production and subsequently require remediation (including hotfix, rollback, fix forward, patch etc.). The frequent failures potentially impair revenue and customer experience, as well as incur significant costs to remediate.
Most customers whom we speak to are unable to proactively predict the risk of a change going into production. In fact, the 2021 State of Testing in DevOps report also indicates that greater than 70% of organizations surveyed are not confident about the quality of their releases. A smaller, but still significant, proportion (15%) “Release and Pray” that their changes won’t degrade production.
Reliability is a key product/service/system quality metric. CFR is one of many reliability metrics. Other metrics include availability, latency, thruput, performance, scalability, mean time between failures, among others. While reliability engineering in software has been an established discipline, we clearly have a problem ensuring reliability.
In order to ensure reliability for software systems, we need to establish practices that plan for, specify, engineer, measure and analyze reliability continuously along the DevOps life cycle. We call this “Continuous Reliability” (CR).
Key Practices for Continuous Reliability
Continuous Reliability derives from the principle of “Continuous Everything” in DevOps. The emergence (and adoption) of Site Reliability Engineering (SRE) principles has led to CR evolving to be a key practice in DevOps and Continuous Delivery. In CR, the focus is to take a continuous proactive approach at every step of the DevOps lifecycle to ensure that reliability goals will be met in production.
This implies that we are able to understand and control the risks of changes (and deployments) before they make it to production.
The key pillars of CR are shown in the figure below:
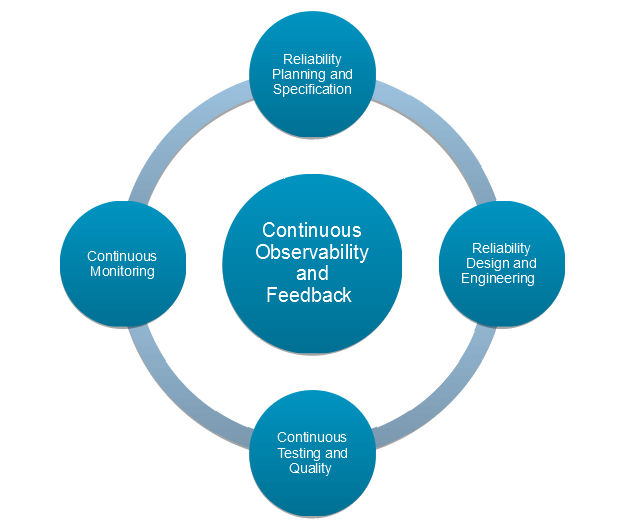
CR is not, however, the purview of site reliability engineers (SREs) alone. Like other DevOps practices, CR requires active collaboration among multiple personas such as SREs, product managers/owners, architects, developers, testers, release/deployment engineers and operations engineers.
Some of the key practices for supporting CR (that are overlaid on top of the core SRE principles) are described below.
1) Continuous Testing for Reliability
Continuous Testing (CT) is an established practice in Continuous Delivery. However, the use of CT for continuous reliability validation is less common. Specifically for validation of the key reliability metrics (such as availability, latency, throughput, performance, scalability), many organizations still use waterfall-style performance testing, where most of the testing is done in long duration tests before release. This not only slows down the deployment, but does an incomplete job of validation.
Our recommended approach is to validate these reliability metrics progressively at every step of the CI/CD lifecycle. This is described in detail in my prior blog on Continuous Performance Testing.
2) Continuous Observability
Observability is also an established practice in DevOps. However, most observability solutions (such as Business Services Reliability) focus on production data and events.
What is needed for CR is to “shift-left” observability into all stages of the CI/CD lifecycle, so that reliability insights can be gleaned from pre-production data (in conjunction with production data). For example, it is possible to glean reliability insights from patterns of code changes (in source code management systems), test results and coverage, as well as performance monitoring by correlating such data with past failure/reliability history in production.
Pre-production environments are more data rich than production environments (in terms of variety); however, most of the data is not correlated and mined for insights. Such observability requires us to set up “systems of intelligence” (SOI, see figure below) where we continuously collect and analyze pre-production data along the CI/CD lifecycle to generate a variety of reliability predictions as and when applications change (see next section).
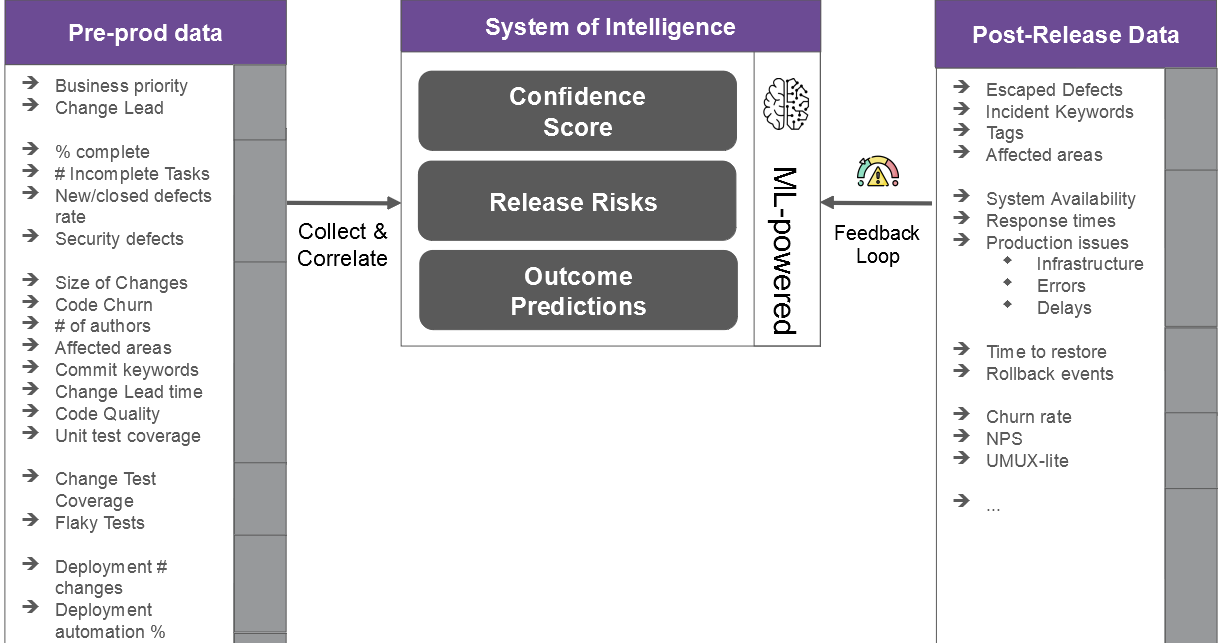
3) Continuous Failure, Risk Insights and Prediction
An observability system in pre-production allows us to continuously assess and monitor failure risk along the CI/CD lifecycle. This allows us to proactively assess (and even predict) the failure risk associated with changes.
For example, we set up a simple SOI for an application (using Google Analytics) where I collected code change data (from the source code management system) as well as history of escaped defects (from past deployments to production). By correlating such data (gradient boosted tree algorithm), I was able to establish an understanding of what code change patterns resulted in higher levels of escaped defects. In this case, I found a significant correlation between code churn and defects leaked (see figure below).
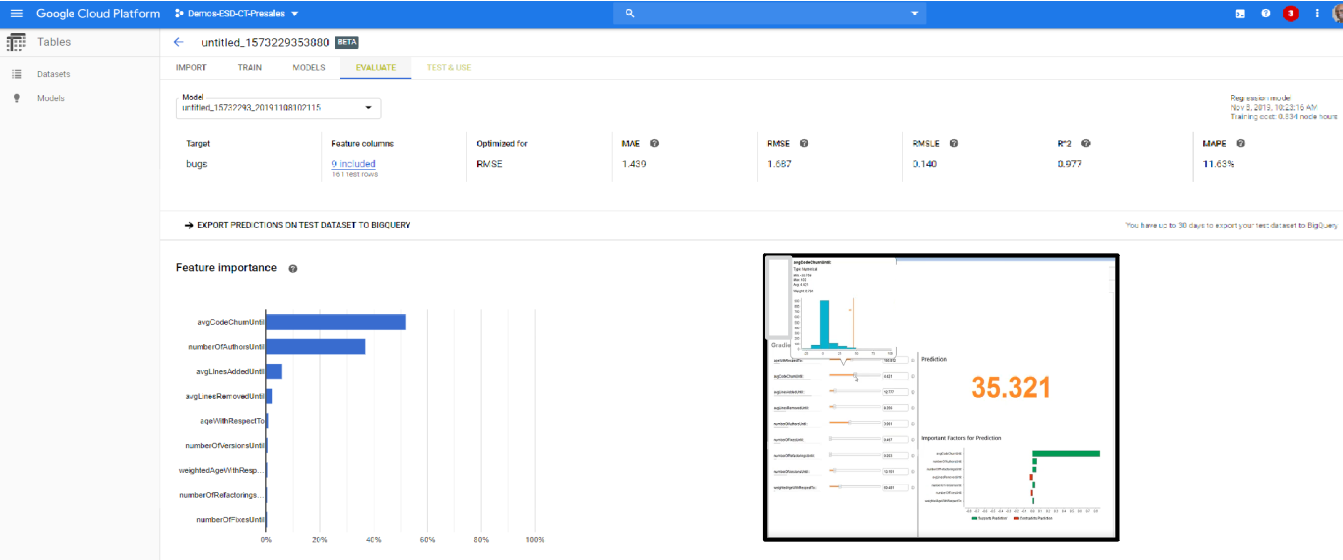
We were then able to use the same analytics to predict how escaped defects would change based on code churn in my current deployment (see inset in the figure above).
While this is a very simple example of reliability prediction using a limited data set, we can do continuous failure risk prediction by exploiting a broader set of data from pre-production, including testing and deployment data.
For example, in my previous article on Continuous Performance Testing, I discussed various approaches for performance testing of component-based applications. Such testing generates a huge amount of data that is extremely difficult to process manually. An observability system can then be used to collect the data to establish baselines of component reliability and performance, and in turn used to generate insights in terms of how system reliability may be impacted by changes in individual application components (or other system components).
4) Continuous Feedback
One of the key benefits of an observability system is to be able to provide quick and continuous feedback to the development/test/release/SRE teams on the risk associated with changes and provide helpful insights on how to address them. This would allow development teams to proactively address these risks before the changes are deployed to production. For example, development teams can be alerted as soon as performing a commit (or a pull request) of the failure risks associated with the changes they have made. Testers can get feedback on the tests that are the most important to run. Similarly, SREs can get early planning insights into the level of error budgets they need to plan for the next release cycle.
Next up: Continuous Quality
Reliability, however, is just one dimension of application/system quality. It does not, for example, fully address how we maximize customer experience that is influenced by other factors such as value to users, ease of use, and more. In order to get true value from DevOps and Continuous Delivery initiatives, we need to establish practices for predictively attaining quality – we call this “Continuous Quality.” I will discuss this in my next blog.