GitHub shared the technology that went into developing Topics, it’s recently launched feature that lets developers tag repositories with descriptive words or phrases. The ultimate goal is to make it easy for developers to discover new projects and to explore GitHub.
Topics is GitHub’s first machine learning project in production, and it’s the first of a series of machine-learning powered features that GitHub will roll out in the coming months. Topic suggestions on public repositories provides a quick and easy way to add tags to repositories in GitHub, and these suggestions all come from recent data science work.
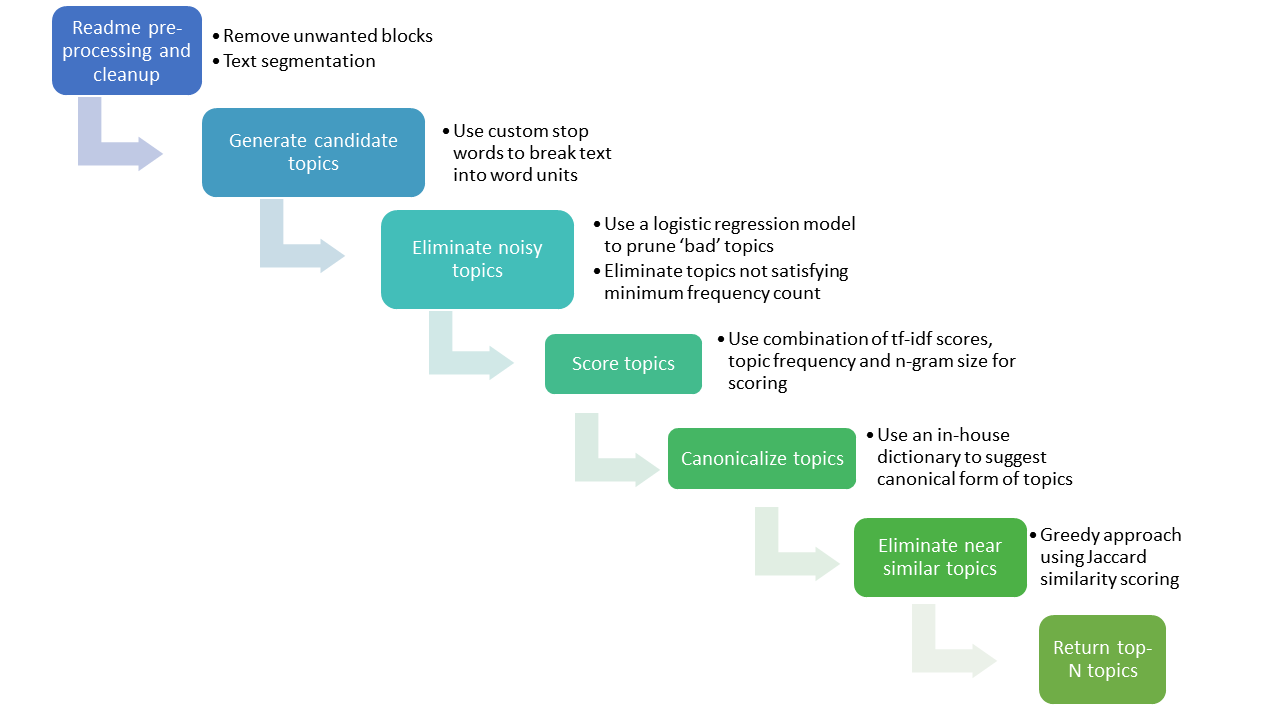
To develop Topics, GitHub started with repository names, descriptions, and READMEs, since they provide functionality, use cases, and features to human readers. From their, GitHub developed a topic extraction framework called repo-topix to learn from the human-readable text that users provide, according to Kavita Ganesan, data scientist and data mining expert, in a blog.
Repo-topix does three things:
- Generates candidate topics from natural language text by incorporating data from millions of other repositories
- Selects the best topics from the set of candidates
- Finds similarities and relationships in topics to facilitate discoverability
According to GitHub, the topics extraction framework is able to discover new topics for any public repository. It also focuses on using lightweight methods that can easily scale as GitHub.com’s repository base grows over the years.
“Our plan for the near future is to evaluate the usage of suggested topics as well as manually created topics to continuously improve suggestions shown to users,” writes Ganesan. “Some of the rejected topics could feed into our topics extraction framework as stop words or as negative examples to our keyword filtering model.”
Ganesan also writes that GitHub plans on exploring topic suggestions on private repositories and with GitHub Enterprise, but in a way that obeys by privacy concerns and eliminates data dependencies.