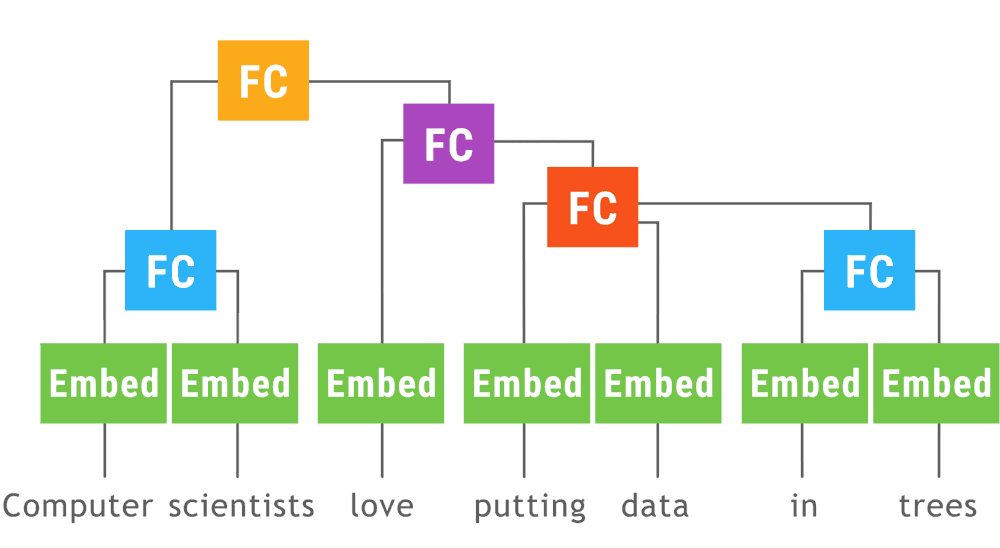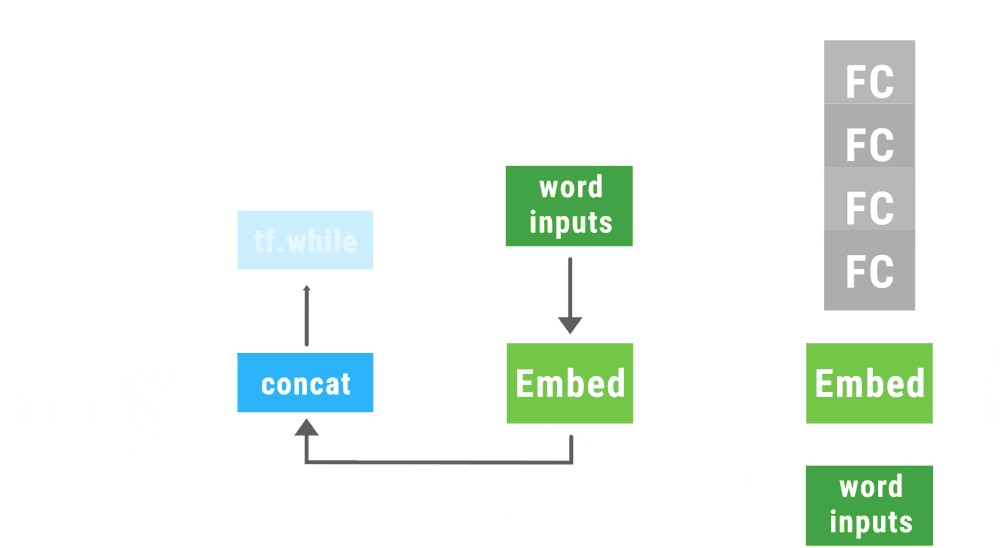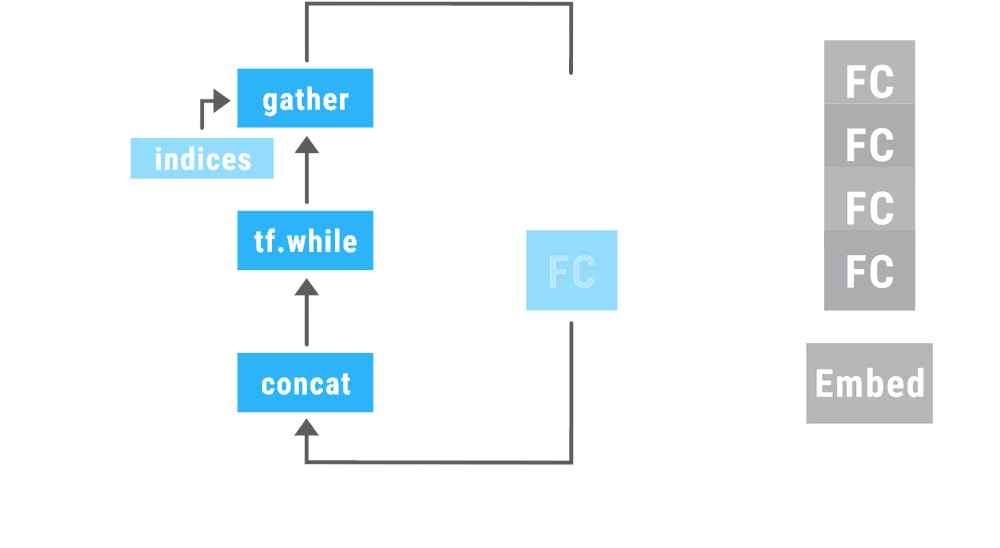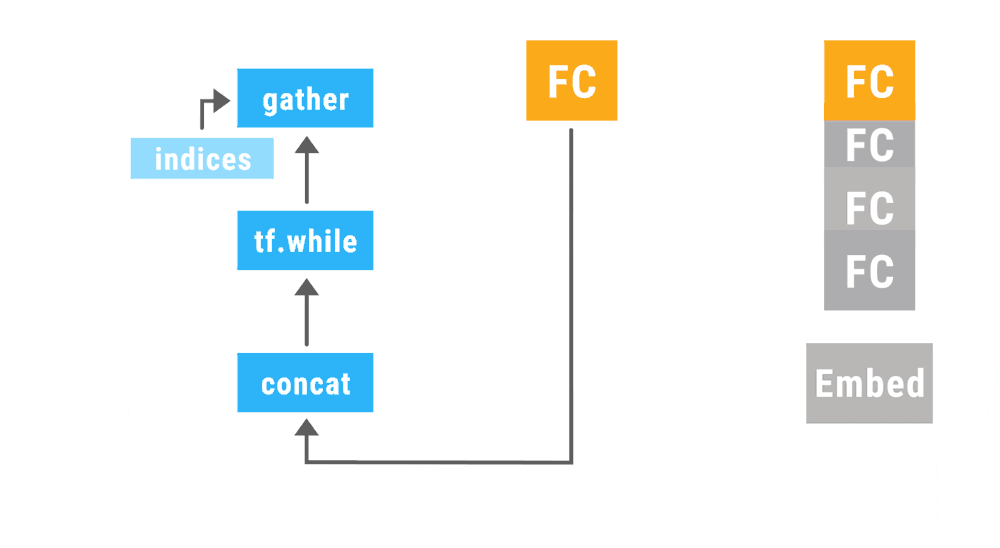
Google wants to help developers implement TensorFlow deep learning models with its release of TensorFlow Fold. TensorFlow Fold was designed to address the challenges developers face when applying models to domains of various sizes and structures.
“In much of machine learning, data used for training and inference undergoes a preprocessing step, where multiple inputs (such as images) are scaled to the same dimensions and stacked into batches,” wrote Google software engineers Marcello Herreshoff, DeLesley Hutchins and Moshe Looks in a blog post. However, according to the engineers, different inputs have different computation graphs, and as a result they don’t batch together well. This leads to poor processor, memory and cache utilization.
(Related: CData creates ODBC reader for Google’s TensorFlow)
TensorFlow Fold is meant to tackle this and bring the benefits of batching to those models.
“The TensorFlow Fold library will initially build a separate computation graph from each input,” the engineers wrote. “Because the individual inputs may have different sizes and structures, the computation graphs may as well. Dynamic batching then automatically combines these graphs to take advantage of opportunities for batching, both within and across inputs, and inserts additional instructions to move data between the batched operations.”
More information is available here.




