More than half a year after the most infamous website rollout in history, HealthCare.gov is still a punch line.
Since a New York Times article last October quoted a specialist working on HealthCare.gov as saying the site contained an astronomical 500 million lines of code, the number has been cited in countless articles and has come to define the site’s failure despite wide skepticism from the software community about its validity.
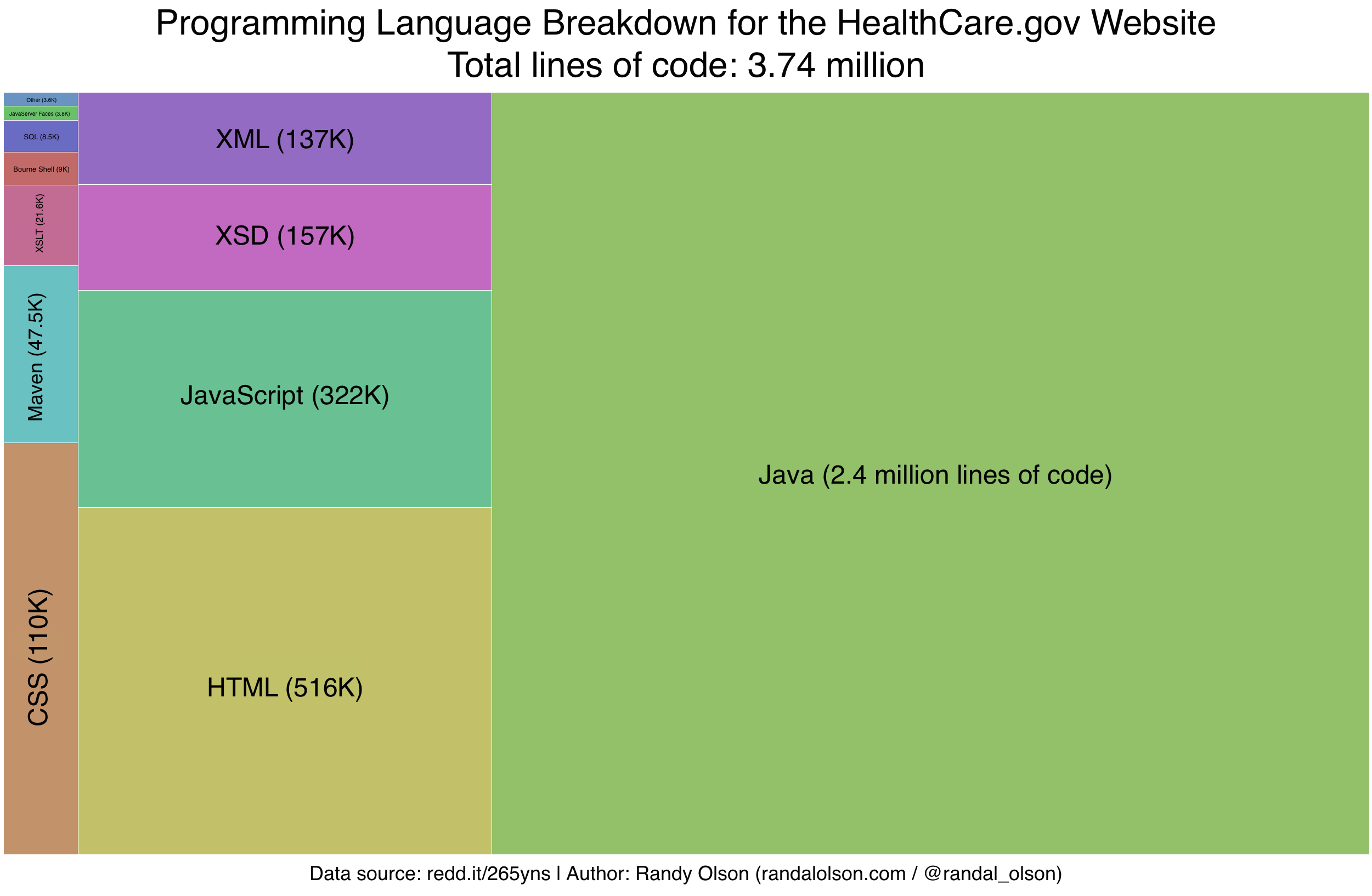
When a new data visualization of codebase sizes went viral this week, a programmer who claims to have worked on HealthCare.gov cleanup from November 2013 through February 2014 took to Reddit to clear up what he said is a false, bloated statistic once and for all. Using the Sourceforge CLOC (Count Lines of Code) tool, the programmer ran an automated code count, finding approximately 3.74 million lines of code on HealthCare.gov, though he acknowledges the true number could be between 5 and 15 million lines to account for the administrative parts of the system.
(Related: Why Healthcare.gov was doomed by legacy systems)
“Having hands-on experience with this software, I would have to assume those [administrative] parts of the system are most likely smaller in implementation than the massive front end that faces the public,” wrote redditor and supposed HealthCare.gov programmer agenaille.
Programmer Randy Olson then condensed the code count into a graph, which shows Java with the most lines of code by far with 2.4 million, followed by HTML with 516,000 and JavaScript with 322,000. So while 3.7 million lines of code is still not exact, it’s far closer to the truth than 500 million.
There’s no way to verify whether this anonymous redditor actually did work on the HealthCare.gov cleanup or not, but ultimately it doesn’t really matter. There’s plenty of free code counting software out there to come to independent conclusions. If HealthCare.gov is to continue serving as the butt of programming jokes, we should at least get our facts straight.



{kind=link}