Following through on its goal of producing the world’s most diverse voice dataset, Mozilla believes it has now released what is now the largest transcribed voice dataset available publicly. The Common Voice project was started by the company as a way to make voice recognition available to everyone. “Most of the data used by large … continue reading
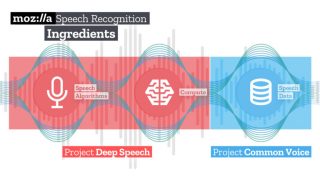
Mozilla announced a mission to help developers create speech-to-text applications earlier this year by making voice recognition and deep learning algorithms available to everyone. Today, the company’s machine learning group is one step closer to completing that mission with the initial open source release of its speech recognition model and voice dataset. “There are only … continue reading
| Cookie | Duration | Description |
|---|---|---|
| cf_use_ob | past | Cloudflare sets this cookie to improve page load times and to disallow any security restrictions based on the visitor's IP address. |
| cookielawinfo-checkbox-advertisement | 1 year | Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category . |
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| CookieLawInfoConsent | 1 year | Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie. |
| JSESSIONID | session | The JSESSIONID cookie is used by New Relic to store a session identifier so that New Relic can monitor session counts for an application. |
| PHPSESSID | session | This cookie is native to PHP applications. The cookie is used to store and identify a users' unique session ID for the purpose of managing user session on the website. The cookie is a session cookies and is deleted when all the browser windows are closed. |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |
| Cookie | Duration | Description |
|---|---|---|
| __atuvc | 1 year 1 month | AddThis sets this cookie to ensure that the updated count is seen when one shares a page and returns to it, before the share count cache is updated. |
| __atuvs | 30 minutes | AddThis sets this cookie to ensure that the updated count is seen when one shares a page and returns to it, before the share count cache is updated. |
| __cf_bm | 30 minutes | This cookie, set by Cloudflare, is used to support Cloudflare Bot Management. |
| Cookie | Duration | Description |
|---|---|---|
| ac_enable_tracking | 1 month | This cookie is set by Active Campaign to denote that traffic is enabled for the website. |
| Cookie | Duration | Description |
|---|---|---|
| __gads | 1 year 24 days | The __gads cookie, set by Google, is stored under DoubleClick domain and tracks the number of times users see an advert, measures the success of the campaign and calculates its revenue. This cookie can only be read from the domain they are set on and will not track any data while browsing through other sites. |
| _ga | 2 years | The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors. |
| _ga_S6PB8V57DG | 2 years | This cookie is installed by Google Analytics. |
| _gat_gtag_UA_846073_1 | 1 minute | Set by Google to distinguish users. |
| _gid | 1 day | Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously. |
| _jsuid | 1 year | This cookie contains random number which is generated when a visitor visits the website for the first time. This cookie is used to identify the new visitors to the website. |
| at-rand | never | AddThis sets this cookie to track page visits, sources of traffic and share counts. |
| CONSENT | 2 years | YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data. |
| iutk | 5 months 27 days | This cookie is used by Issuu analytic system to gather information regarding visitor activity on Issuu products. |
| uvc | 1 year 1 month | Set by addthis.com to determine the usage of addthis.com service. |
| vuid | 2 years | Vimeo installs this cookie to collect tracking information by setting a unique ID to embed videos to the website. |
| WMF-Last-Access | 1 month 14 hours 26 minutes | This cookie is used to calculate unique devices accessing the website. |
| Cookie | Duration | Description |
|---|---|---|
| __Host-GAPS | 2 years | This cookie allows the website to identify a user and provide enhanced functionality and personalisation. |
| _pxhd | session | Used by Zoominfo to enhance customer data. |
| IDE | 1 year 24 days | Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile. |
| loc | 1 year 1 month | AddThis sets this geolocation cookie to help understand the location of users who share the information. |
| mc | 1 year 1 month | Quantserve sets the mc cookie to anonymously track user behaviour on the website. |
| test_cookie | 15 minutes | The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies. |
| VISITOR_INFO1_LIVE | 5 months 27 days | A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface. |
| YSC | session | YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages. |
| yt-remote-connected-devices | never | YouTube sets this cookie to store the video preferences of the user using embedded YouTube video. |
| yt-remote-device-id | never | YouTube sets this cookie to store the video preferences of the user using embedded YouTube video. |
| yt.innertube::nextId | never | This cookie, set by YouTube, registers a unique ID to store data on what videos from YouTube the user has seen. |
| yt.innertube::requests | never | This cookie, set by YouTube, registers a unique ID to store data on what videos from YouTube the user has seen. |
| Cookie | Duration | Description |
|---|---|---|
| __gpi | 1 year 24 days | No description |
| __Secure-YEC | 1 year 1 month | No description |
| _heatmaps_g2g_100754890 | 10 minutes | No description |
| _techvalidate_session | session | No description |
| cf_7166_id | 20 years | No description |
| cf_7166_person_last_update | session | No description |
| f5avraaaaaaaaaaaaaaaa_session_ | session | No description available. |
| GoogleAdServingTest | session | No description |
| Gyazo_cfwoker | 7 years 2 months 17 days 7 hours | No description |
| incap_ses_451_2783402 | session | No description |
| incap_ses_769_2783402 | session | No description |
| loglevel | never | No description available. |
| m | 2 years | No description available. |
| nlbi_2783402 | session | No description |
| prism_252377639 | 1 month | No description |
| TS011605d9 | session | No description |
| ustream-guest | session | No description available. |
| visid_incap_2783402 | 1 year | No description |
| xtc | 1 year 1 month | No description |