Following through on its goal of producing the world’s most diverse voice dataset, Mozilla believes it has now released what is now the largest transcribed voice dataset available publicly.
The Common Voice project was started by the company as a way to make voice recognition available to everyone. “Most of the data used by large companies isn’t available to the majority of people. We think that stifles innovation. So we’ve launched Common Voice, a project to help make voice recognition open and accessible to everyone,” Mozilla website states. According to the company Common Voice is just one part of its initiative to provide a more diverse voice technology ecosystem. It also is working on open source Speech-to-Text and Text-to-Speech engines as well as training models through its DeepSpeech project.
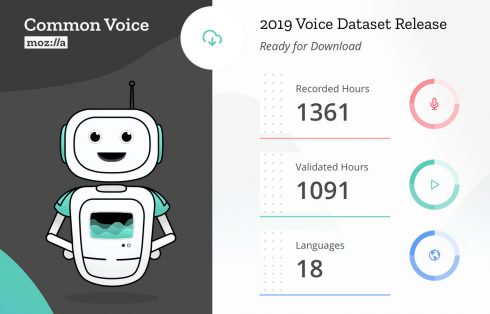
According to Mozilla, the Common Voice dataset is now made up of about 1,400 hours of voice clips from over 42,000 people.
The updated Common Voice dataset includes 18 different languages, such as English, French, German, Mandarin Chinese, Welsh, Kabyle, Dutch, Hakha-Chan, Esperanto, Farsi, Basque, and Spanish. The company first enabled multi-language support in June 2018, at which point it only had three languages.
“As a community-driven project, people around the world who care about having a voice dataset in their language have been responsible for each new launch — some are passionate volunteers, some are doing this as part of their day jobs as linguists or technologists. Each of these efforts require translating the website to allow contributions and adding sentences to be read,” George Roter, director of open innovation programs at Mozilla, wrote in a post.
Mozilla explained that it maintains diversity by allowing contributors to provide metadata such as their age, sex, and accent so that their voice clips can be accurately tagged with useful information. Other datasets that don’t take this approach often end up being hand-crafted to be diverse, and thus end up with problems such as having an equal number of men and women, or are as diverse as the “found” data. For example, the TEDLIUM corpus of voice data from TED talks is made up of three times more men than women, Mozilla explained.
According to Mozilla, in many instances, a new language launching in Common Voice also marks the first time that language has been represented on the Internet. “These community efforts are proof that all languages—not just ones that can generate high revenue for technology companies—are worthy of representation. We’ll continue working with these communities to ensure their voices are represented and even help make voice technology for themselves,” Roter wrote.
Other recent efforts Mozilla has made in this area include partnering with the Deutsche Gesellschaft für Internationale Zusammenarbeit (GIZ) and co-hosting a hackathon in Kigali to create a speech corpus for Kinyarwanda. Mozilla explained that this laid the groundwork for local technologists in Rwanda to being creating open-source voice technologies in their own language.
Since opening up multi-language support in Common Voice eight months ago, Mozilla has made improvements to the contribution process, such as improved prompts, the ability to easily move between speak and listen, the ability to opt-out of speaking for a particular session, and new functionality for reviewing, re-recording, and skipping clips. It also added the option to create a saved profile, enabling contributors to keep track of their progress and metrics across multiple languages.
“From the onset, our vision for Common Voice has been to build the world’s most diverse voice dataset, optimized for building voice technologies. We also made a promise of openness: we would make the high quality, transcribed voice data that was collected publicly available to startups, researchers, and anyone interested in voice-enabled technologies,” Roter wrote.




