Mozilla announced a mission to help developers create speech-to-text applications earlier this year by making voice recognition and deep learning algorithms available to everyone. Today, the company’s machine learning group is one step closer to completing that mission with the initial open source release of its speech recognition model and voice dataset.
“There are only a few commercial quality speech recognition services available, dominated by a small number of large companies. This reduces user choice and available features for startups, researchers or even larger companies that want to speech-enable their products and services,” Sean White, vice president of technology strategy at Mozilla, wrote in a blog post.
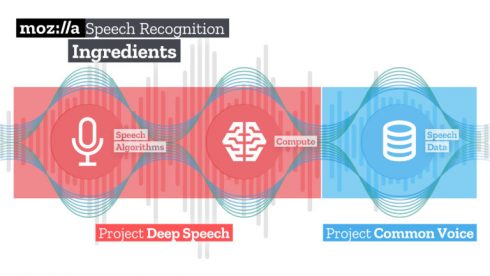
DeepSpeech is Mozilla’s way of changing that. Based on Baidu’s Deep Speech research, Project DeepSpeech uses machine learning techniques to provide speech recognition almost as accurate as humans.
“Together with a community of likeminded developers, companies and researchers, we have applied sophisticated machine learning techniques and a variety of innovations to build a speech-to-text engine that has a word error rate of just 6.5% on LibriSpeech’s test-clean dataset,” White wrote.
The initial release includes pre-built packages for Python, NodeJS and a command-line binary.
In addition, the company is releasing “the world’s second largest publicly available voice dataset.” Through Project Common Voice, Mozilla campaigned nearly 20,000 people worldwide to donate voice recordings to an open repository. Today, the project includes nearly 400,000 recordings and 500 hours of speech that anyone can download.
“When we look at today’s voice ecosystem, we see many developers, makers, startups, and researchers who want to experiment with and build voice-enabled technologies. But most of us only have access to fairly limited collection of voice data; an essential component for creating high-quality speech recognition engines,” Michael Henretty, an engineer at Mozilla, wrote in a post. “By providing this new public dataset, we want to help overcome these barriers and make it easier to create new and better speech recognition systems.”
The public dataset is starting off with English, but aims to support every language.