Databricks announced new plans to make working with deep learning and analytics easier for the Apache Spark community at this week’s Spark Summit in San Francisco. The company unveiled a new serverless platform, a new Apache Spark library for deep learning, and the availability of its stream processing solution.
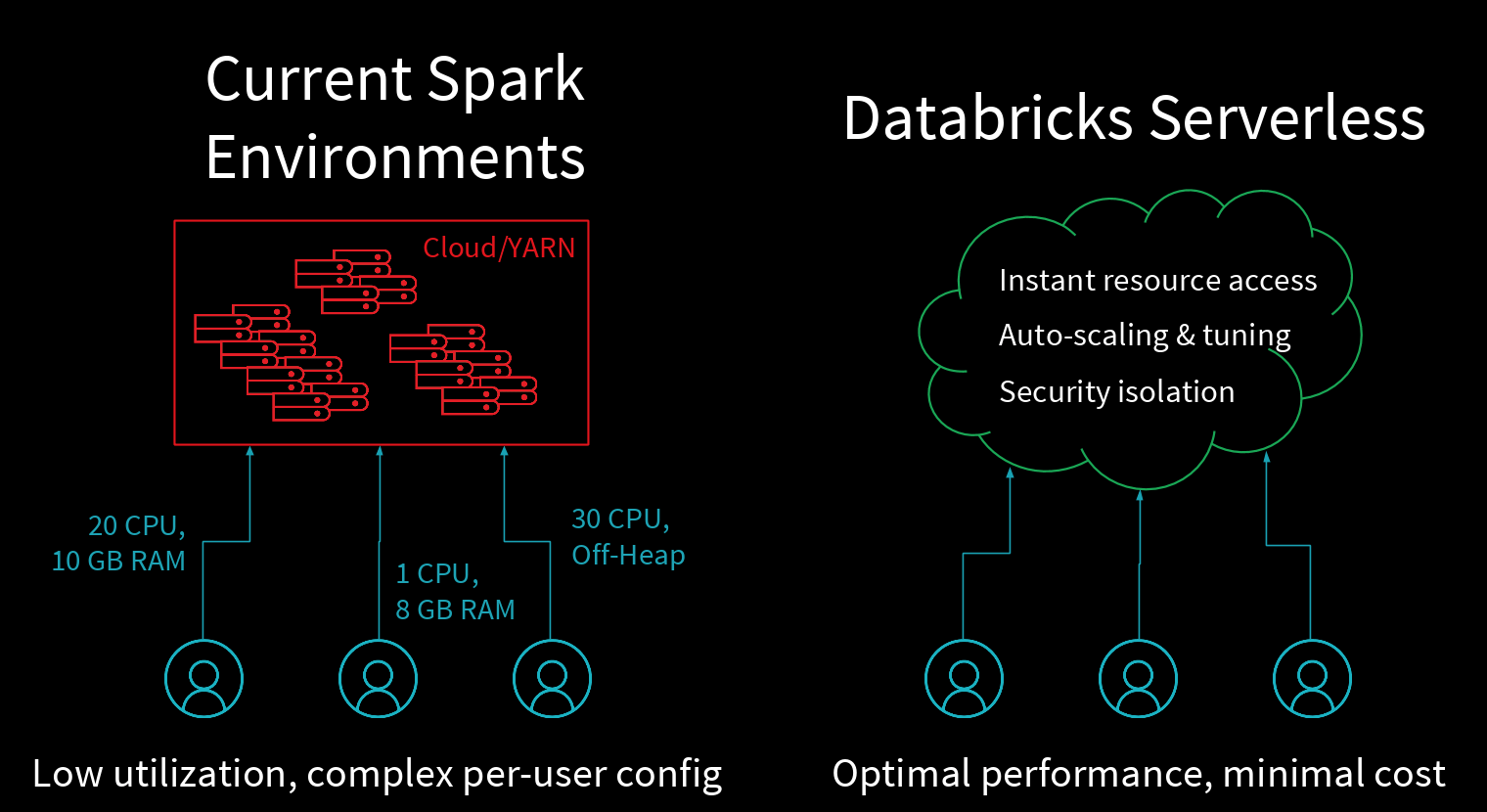
Databricks Serverless is a fully managed computing platform for Apache Spark that improves productivity and performance in data science teams. “As enterprises scale their use of Apache Spark, hundreds of data scientists, data engineers and business users need to use the platform. Traditional cloud and on-premise platforms require teams or individuals to manage their own Spark clusters in order to enforce data security, isolate workloads, and configure resource allocation,” said Ali Ghodsi, cofounder and chief executive officer at Databricks. “This approach is costly and highly complex, as every team must learn to manage its own clusters. With Databricks Serverless, organizations can use a single, automatically managed pool of resources and get best-in-class performance for all users at dramatically lower costs.”
The solution provides auto-managed configuration of clusters, scaling of local storage, adaptation to multiple users sharing the cluster, and security.
Deep Learning Pipelines is the company’s new open-source library for scaling out deep learning in Apache Spark. With the pipelines package, users can call deep learning libraries within existing Spark machine learning workflows, transfer learning of deep learning models, leverage Spark’s distributed computation engine, leverage AI, and work with complex data.
“This is a huge step in furthering Databricks’ mission to democratize artificial intelligence and data science,” said Matei Zaharia, cofounder and chief technologist at Databricks. “This work has the potential to accomplish for deep learning what Spark did for Big Data, which is to make it approachable to a much broader audience, from data scientists to business analysts.”
Lastly, the company announced the general availability of Structured Streaming, a new API for end-to-end streaming. Features include custom stateful processing, production monitoring, and connection to common data sources.
“With Structured Streaming, customers can now get best-in-class latency while simultaneously benefitting from Spark’s much simpler streaming APIs and lowering the operational cost of their streaming applications by up to five times,” said Zaharia. “We are excited to keep working with the open source community to build out Structured Streaming and to deliver continuous application capabilities to our customers.”



