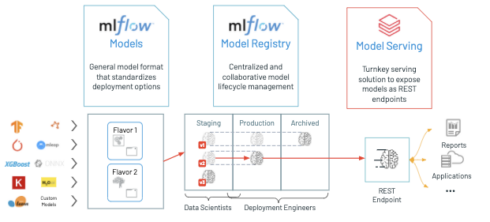
Databricks introduced a public preview of GPU and LLM optimization support for Databricks Model Serving. This new feature enables the deployment of various AI models, including LLMs and Vision models, on the Lakehouse Platform.
Databricks Model Serving offers automatic optimization for LLM Serving, delivering high-performance results without the need for manual configuration. According to Databricks, it’s the first serverless GPU serving product built on a unified data and AI platform, allowing users to create and deploy GenAI applications seamlessly within a single platform, covering everything from data ingestion to model deployment and monitoring.
Databricks Model Serving simplifies the deployment of AI models, making it easy even for users without deep infrastructure knowledge. Users can deploy a wide range of models, including natural language, vision, audio, tabular, or custom models, regardless of how they were trained (from scratch, open-source, or fine-tuned with proprietary data).
Just log your model with MLflow, and Databricks Model Serving will automatically prepare a production-ready container with GPU libraries like CUDA and deploy it to serverless GPUs. This fully managed service handles everything from managing instances, maintaining version compatibility, to patching versions. It also automatically adjusts instance scaling to match traffic patterns, saving on infrastructure costs while optimizing performance and latency.
Databricks Model Serving has introduced optimizations for serving large language models (LLM) more efficiently, resulting in up to a 3-5x reduction in latency and cost. To use Optimized LLM Serving, you simply provide the model and its weights, and Databricks takes care of the rest, ensuring your model performs optimally.
This streamlines the process, allowing you to concentrate on integrating LLM into your application rather than dealing with low-level model optimization. Currently, Databricks Model Serving automatically optimizes MPT and Llama2 models, with plans to support additional models in the future.



