Databricks has announced new capabilities to its Unified Analytics platform designed to help lower the barrier for enterprises utilizing AI. The company introduced MLflow, Databricks runtime for ML and Databricks Delta at the Spark + AI Summit in San Francisco this week.
According to the company, the new capabilities aim to simplify distributed machine learning and the machine learning workflow, as well as add data reliability and performance at scale.
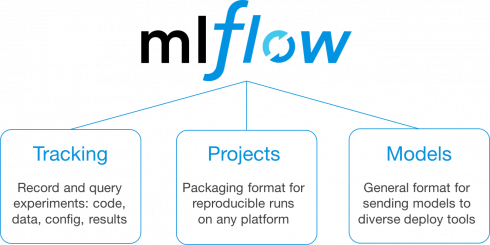
The company explained that data is essential to machine learning, but using machine learning in production can be difficult due to the fact that the development process lacks the tools to reproduce results, track experiments, and manage models. MLflow, an open-source toolkit for simplifying the machine learning workflow, was created in response to this problem.
With MLflow, Databricks says organizations will be able to package code for reproducible runs, execute and compare hundreds of parallel experiments, leverage any hardware or software platform, and deploy models to production. MLflow also integrates with Apache Spark, SciKit-Learn, TensorFlow, and other open-source machine learning frameworks.
“When it comes to building a web or mobile application, organizations know how to do that because we’ve built toolkits, workflows, and reference architectures. But there is no toolkit for machine learning, which is forcing organizations to piece together point solutions and secure highly specialized skills to achieve AI,” said Matei Zaharia, co-founder and chief technologist at Databricks. “MLflow is a unified toolkit for developing machine learning applications in a repeatable manner while having the flexibility to deploy reliably in production across multiple cloud environments.”
Databricks Runtime for ML is meant to eliminate the complexities of distributed computing needed for deep learning. The company also introduced GPU support for AWS and Microsoft Azure to make it possible to scale deep learning. Data scientists will be able to feed data sets to models, evaluate, and deploy AI models on one unified engine, Databricks explained.
Finally, the company aims to simplify data engineering with the introduction of Databricks Delta, a data management system for simplifying large-scale data management. With this solution, Databricks says organizations will not be forced to make tradeoffs between storage system properties or spend resources moving data across systems. Hundreds of applications will now be able to reliably upload, query, and update data at massive scale and low cost.
“To derive value from AI, enterprises are dependent on their existing data and ability to iteratively do machine learning on massive data sets. Today’s data engineers and data scientists use numerous, disconnected tools to accomplish this, including a zoo of machine learning frameworks,” said Ali Ghodsi, co-founder and CEO at Databricks. “Both organizational and technology silos create friction and slow down projects, becoming an impediment to the highly iterative nature of AI projects. Unified Analytics is the way to increase collaboration between data engineers and data scientists and unify data processing and AI technologies.”