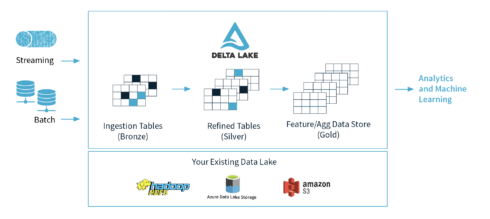
Databricks has announced it is donating its open-source data lakes project to the Linux Foundation. Delta Lake is designed to improve the reliability, quality and performance of data lakes.
Databricks first announced the project in April. “Today, nearly every company has a data lake they are trying to gain insights from, but data lakes have proven to lack data reliability. Delta Lake has eliminated these challenges for hundreds of enterprises. By making Delta Lake open source, developers will be able to easily build reliable data lakes and turn them into ‘Delta Lakes’,” Ali Ghodsi, cofounder and CEO at Databricks, said at the time.
As a Linux Foundation project, Delta Lake will be used as an open standard for data lakes. It will adopt an open governance model and provide a framework for long-term stewardship.
“Bringing Delta Lake under the neutral home of the Linux Foundation will help the open source community dependent on the project develop the technology addressing how big data is stored and processed, both on-prem and in the cloud,” said Michael Dolan, VP of strategic programs at the Linux Foundation. “The Linux Foundation helps open source communities leverage an open governance model to enable broad industry contribution and consensus building, which will improve the state of the art for data storage and reliability.”
Other features of the project include:
- ACID transactions: The project features the ability to have multiple data pipelines reading and writing data concurrently
- Scalable metadata handling: The project treats metadata just like data and leverages Spark’s distributed processing power
- Time travel: Snapshots of data that enables developers to access or revert to earlier versions
- Open format: All data is stored in Apache Parquet format
- Unified batch and streaming source and sick
- Schema enforcement and evolution
- Audit history
- Updates and delete capabilities
- 100% compatibility with Apache Spark API




