Milvus is an open-source vector database that is capable of managing large quantities of both structured and unstructured data to accelerate the development of next-generation data fabric.
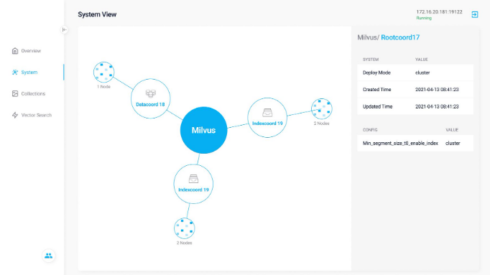
According to Zilliz, the database company that created the project, Milvus is built for scalable similarity search used by enterprises spanning several industries. It also works with distributed architecture and can simply scale as data volumes and workloads increase.
Milvus supports DML operations as well as offers near real-time search of vectors on a trillion-byte scale.
Zilliz has recently announced several contributions to the Milvus 2.1 release. The release of Milvus 2.1 works to further bridge the gap between data pools, remove data silos, and offer performance and availability enhancements in order to address the most common concerns of developers.
“Data silos can now be better integrated and linked, enabling businesses to unlock the full potential of their data,” said Xiaofan James Luan, a project maintainer for Milvus who also serves as the director of engineering at Zilliz. “When it comes to unstructured data, solutions offered by industry incumbents tend to be add-on capabilities or tools in a legacy database management system, whereas Milvus is designed around unstructured data from day one and is now offering more built-in capabilities to unlock more powerful and integrated data processing.”
With the 2.1 update, Milvus users gain access to performance improvements, including the reduction of search latency on million-scale datasets to five milliseconds. Additionally, deployment and ops workflow will be simplified.
Luan said, “As data infrastructure for unstructured data, Milvus is revolutionary because it processes vector embeddings and not just strings. In the future, Zilliz, the company founded by the creators of Milvus, seeks to build an ecosystem of solutions around Milvus, and some of the projects that will contribute to this have already surfaced, including Towhee, our open-source vector data ETL framework, and Feder, an interactive visualization tool for unstructured data. With Milvus 2.1 and the new demos, users can see how these products can come together to solve a series of problems that involve unstructured data.”