Data has become more important than ever as businesses look to gain new insights and bring new value to customers. The problem, however, is an overwhelming amount of data between the tens if not hundreds of SaaS services, databases, and file formats being used.
“If you can’t connect to that data, then you can’t govern it. You can’t manage it. You can’t analyze it. You can’t report on it,” said Eric Madariaga, co-founder and Chief Marketing Officer at CData.
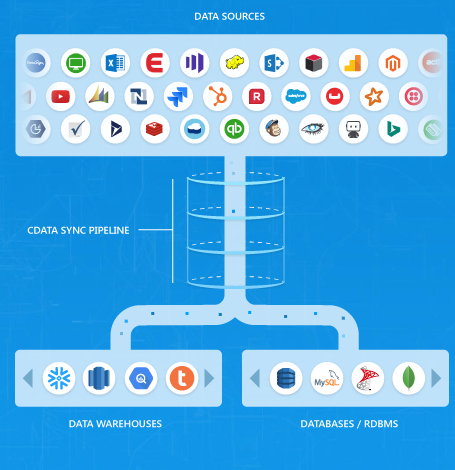
To help organizations connect to and consolidate all of that data, CData provides a universal data pipeline called CData Sync, which enables users to replicate any data source to any database or data warehouse. Designed to support modern ETL and ELT scenarios, the product offers automated iterative data extraction, dynamic schema replication, comprehensive logging, and transaction monitoring.
RELATED CONTENT:
The value of embedding data virtualization
Simplify the way you connect to data sources and tools with CData Python Connectors
Known for their drivers, adapters, and connectors for real-time data access, the company offers CData Sync to support data warehousing projects and as a better solution to access data from APIs that might enforce rate limiting or transaction fees. With CData Sync, “there are scenarios where it is easier, faster, and more cost efficient to move data from one place into your data warehouse, database, or whatever data store you want and then be able to run queries, analytics and business intelligence reporting,” said Madariaga. The solution provides support for more than 100 enterprise data sources to a variety of data destinations, such as Cloud Data Warehouses (Snowflake, Redshft, Big Query, S3 etc.), or Relational Databases (Oracle, SQL Server etc.).
Sync is built to run equally as well on-premise or in the cloud, enabling better control and security. “In our scenario, we are delivering software. You can run the software on-premise, or load a preconfigured AMI or Azure instance, and everything remains completely under your control. The data is always going through your networks, or the networks that you configured and trust,” said Madariaga.
Additionally, the company recently released a free version of CData Sync for ETL/ELT data movement and data warehousing. It will support a subset of free sources and destinations, such as Apache Derby, MariaDB, PostgreSQL, BugZilla, GitHub, Google Calendar, LinkedIn, Microsoft Common Data Service, and Slack. More details are available here.
“Our focus at CData is enabling businesses to connect with their data however they want, no matter how they want to integrate,” said Madariaga. “We support every organization’s business intelligence, analytics, data discovery, data governance, and data management tools. Regardless of technology, our goal is to be able to support all those operations transparently, without our customers having to use various bits and pieces in different places.”
Looking forward, CData will continue to extend CData Sync with new data sources and enhancements for handling data.
Content provided by SD Times and CData



