
SQL is the prime building block of the modern enterprise. All those exciting applications, nifty mobile apps and massive back-end projects are, essentially, useless without the data behind them. That data may not be so important at runtime if the application is just saving logs or form information, but at the end of the day, … continue reading

Hortonworks, one of the three major Hadoop vendors, announced yesterday that it has been collaborating with HP to improve Apache Spark. The work has already yielded faster sort and in-memory computation for the project, as well as improved performance and usage for scalability. Hortonworks also announced the inclusion of Apache Kafka and Storm in its … continue reading

Yahoo has released CaffeOnSpark, which brings the fruits of two University of California, Berkeley projects together: vision-focused deep learning framework Caffe, and Big Data processing engine Apache Spark. Without the aid of Spark, Caffe can process up to 60 million images per day. Those numbers come from benchmarks on a single NVIDIA GPU, so the … continue reading
The database revolution happened a few years back, when NoSQL options stormed the world. Today, however, a second wave of innovation in data storage has been unleashed in the form of Apache Arrow. Arrow builds a standard for columnar in-memory analytics, and will provide a unified data structure, algorithms and cross-language bindings. The overall goal … continue reading

The Apache Hadoop project took off in enterprises over a fairly short period of time. Four or five years ago, Hadoop was just becoming a “thing” for enterprise data processing and experimentation. MapReduce was at the heart of that thing, and Spark was still only a research project at the University of California at Berkeley. … continue reading

To paraphrase that great thinker, Ferris Bueller: “Technology moves pretty fast. It you don’t look around once in a while, you could miss it.” So, to get 2016 rolling, we’ve asked luminaries and thought leaders in the software development space to look around and tell us what they expect from the field this year. Kelly … continue reading

Apache Spark 1.6, which shipped yesterday, offers performance enhancements that range from faster processing of the Parquet data format to better overall performance for streaming state management. As a large-scale data processing platform, Apache Spark has untethered itself from the Hadoop platform. As a result, Spark can be used against key-value stores and other types … continue reading

Mirantis has released a new version of its OpenStack distribution. Version 7.0 includes bug fixes, new Hadoop and Spark support, and integrations with Cloud Foundry and Kubernetes. For existing Mirantis users, the upgrade path to version 7.0 comes with rollback capabilities. That should allow users to implement this new version easily, helping them to utilize … continue reading

When Apache Hadoop burst onto the scene, it changed the game not only for batch processing and data storage, but also for analytics. Tableau was one of the first visual analytics companies to support Hadoop, and now it’s feeling a similar tug from Apache Spark and the streaming revolution. Dustin Smith, product marketing manager at … continue reading

SAP yesterday introduced HANA Vora: a new in-memory query engine for Apache Spark. This new engine allows analysis to be undertaken in a more interactive and iterative manner. The new engine will be available to customers later this month. Quentin Clark, CTO and member of the Global Managing Board of SAP, explained the goals of … continue reading
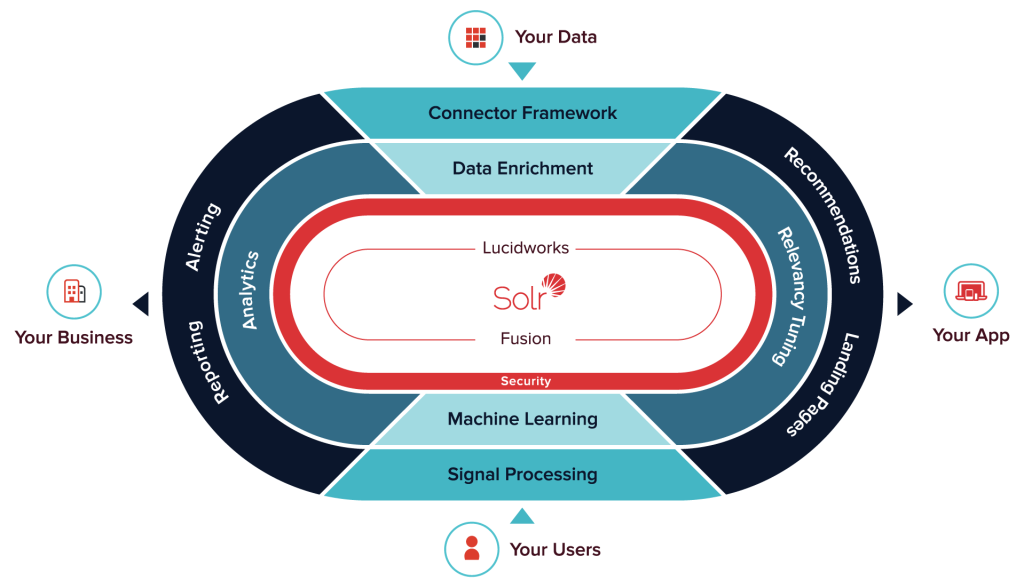
Lucidworks has released version 2.0 of Fusion, its enterprise Big Data search product built on Apache Solr storage architecture, with Apache Spark integration and a revamped SiLK dashboard. Fusion 2.0’s Spark integration within its data-processing layer enables real-time analytics within the enterprise search platform, adding Spark to the Solr architecture to accelerate data retrieval and … continue reading

Databricks has announced the general availability of its cloud-hosted data platform, formerly known as Databricks Cloud. Less than a week after announcing the release of Apache Spark 1.4, Databricks debuted its cloud platform at Spark Summit, which has support for R-language notebooks; version-control and source-code change tracking from within Databricks; private notebook permissions management; and … continue reading