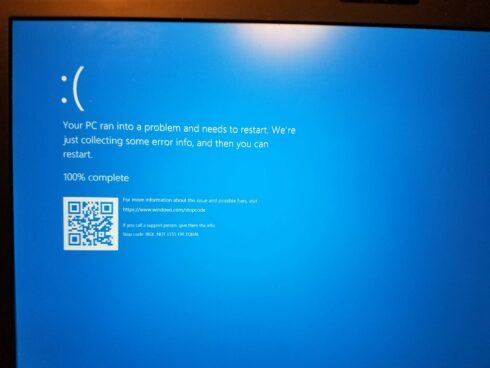
This morning, a number of major systems suffered an outage due to a bad CrowdStrike update. CrowdStrike is an endpoint protection system that runs in the background of a lot of enterprise computers to secure them, and the update caused Windows machines running the updated software to crash.
The software update only affected Windows operating systems; CrowdStrike instances running on Linux and Mac did not cause problems.
Because the use of CrowdStrike and Windows is so prevalent among businesses, the outages were widespread, affecting several major airlines that had to delay/cancel flights, 911 operations, healthcare facilities, and more.
“The current event appears – even in July – that it will be one of the most significant cyber issues of 2024. The damage to business processes at the global level is dramatic,” said Omer Grossman, CIO at CyberArk.
CrowdStrike CEO George Kurtz said in an X post that a fix for the issue had been made available. “This is not a security incident or cyberattack,” he wrote. “The issue has been identified, isolated and a fix has been deployed. We refer customers to the support portal for the latest updates and will continue to provide complete and continuous updates on our website. We further recommend organizations ensure they’re communicating with CrowdStrike representatives through official channels. Our team is fully mobilized to ensure the security and stability of CrowdStrike customers.”
Satya Nadella, CEO of Microsoft also said that it was working closely with CrowdStrike to help get customers back online.
Even though there is a fix available, it could still take days for these outages to resolve. “It turns out that because the endpoints have crashed – the Blue Screen of Death – they cannot be updated remotely and this problem must be solved manually, endpoint by endpoint,” said Grossman.
This event highlighted the problem with the majority of companies relying on just a few large technology vendors, such as Windows. According to Omkhar Arasaratnam, general manager of the Open Source Security Foundation (OpenSSF), these monocultural supply chains are inherently fragile.
“Good system engineering tells us that changes in these systems should be rolled out gradually, observing the impact in small tranches vs. all at once,” said Arasaratnam. “More diverse ecosystems can tolerate rapid change as they’re resilient to systemic issues.”
Marcus Merrell, principal test strategist at Sauce Labs, agrees that an update like this should have been rolled out slowly over a period of several hours or days rather than “risk crippling the entire planet with one large update.”
He continued, “Everything is software and software is everything – it’s more interconnected and interdependent than ever. If the software update release going out there affects not just your users but your users ‘ users, you must slow-roll the release over a period of hours or days, rather than risk crippling the entire planet with one large update.”
He also believes this outage highlights the need for better software quality. A recent survey from Sauce Labs found that 67% of respondents had at some point pushed code to production before testing it, and 28% say they do that regularly.
According to Merrell, companies need to assess the risks vs benefit of any potential release. “The equation is simple: what is the risk of not shipping a code versus the risk of shutting down the world,” he said. “The vulnerabilities fixed in this update were pretty minor by comparison to ‘planes don’t work anymore’, and will likely have the knock-on effect of people not trusting auto-updates or security firms full stop, at least for a while.”
You may also like…
The secret to better products? Let engineers drive vision
Microsoft gives up its observer seat on OpenAI’s board