Google has announced a new TensorFlow runtime designed to make it easier to build and deploy machine learning models across many different devices.
The company explained that ML ecosystems are vastly different than they were 4 or 5 years ago. Today, innovation in ML has led to more complex models and deployment scenarios that require increasing compute needs.
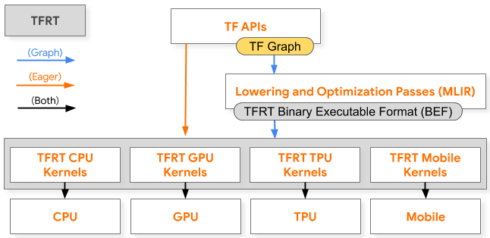
To address these new needs, Google decided to take a new approach towards a high-performance low-level runtime and replace the current TensorFlow stack that is optimized for graph execution, and incurs non-trivial overhead when dispatching a single op.
The new TFRT provides efficient use of multithreaded host CPUs, supports fully asynchronous programming models, and focuses on low-level efficiency and is aimed at a broad range of users such as:
- researchers looking for faster iteration time and better error reporting,
- application developers looking for improved performance,
- and hardware makers looking to integrate edge and datacenter devices into TensorFlow in a modular way.
It is also responsible for the efficient execution of kernels – low-level device-specific primitives – on targeted hardware, and playing a critical part in both eager and graph execution.
“Whereas the existing TensorFlow runtime was initially built for graph execution and training workloads, the new runtime will make eager execution and inference first-class citizens, while putting special emphasis on architecture extensibility and modularity,” Eric Johnson, TRFT product manager, and Mingsheng Hong, TFRT tech lead, wrote in a post.
To achieve higher performance, TFRT has a lock-free graph executor that supports concurrent op execution with low synchronization overhead and has decoupled device runtimes from the host runtime, the core TFRT component that drives host CPU and I/O work.
The runtime is also tightly integrated with MLIR’s compiler infrastructure to generate and optimized, target-specific representation of the computational graph that the runtime executes.
“Together, TFRT and MLIR will improve TensorFlow’s unification, flexibility, and extensibility,” Johnson. and Hong wrote.
TFRT will be integrated into TensorFlow, and will be enabled initially through an opt-in flag, giving the team time to fix any bugs and fine-tune performance. Eventually, it will become TensorFlow’s default runtime.
Additional details are available here.




