It’s been two years since Apache Spark 1.0 was released, and today Databricks is giving everyone a preview for what is to come in version 2.0. According to the company, the upcoming version focuses on three major themes: easier, faster and smarter.
“Spark 2.0 builds on what we have learned in the past two years, doubling down on what users love and improving on what users lament,” wrote Reynold Xin, cofounder of Databricks, in a blog post. “Whereas the final Apache Spark 2.0 release is still a few weeks away, this technical preview is intended to provide early access to the features in Spark 2.0 based on the upstream codebase. This way, you can satisfy your curiosity to try the shiny new toy, while we get feedback and bug reports early before the final release.”
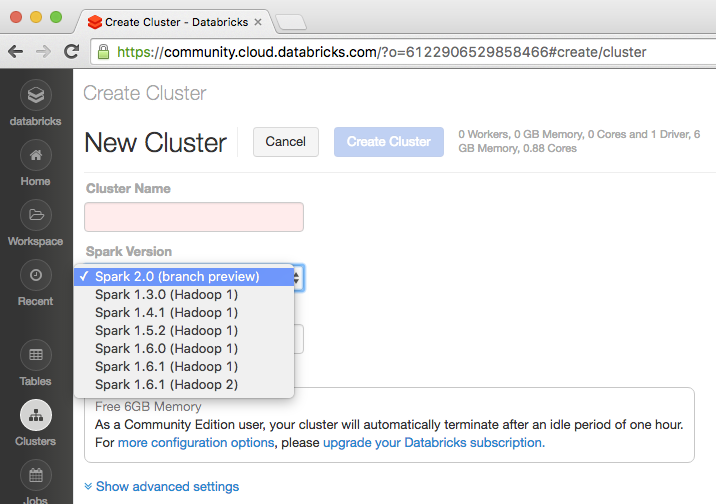
The technical preview of Spark 2.0 is available in the company’s cloud-based Big Data platform, Databricks Community Edition.
(Related: Big Data meets agriculture)
In an attempt to make working with Spark easier, the company focused on two areas: standard SQL support and streamlined APIs. A new ANSI SQL parser has been introduced, as well as support for subqueries in order to expand Spark’s SQL capabilities. On the API side, Spark 2.0 features the ability to unify DataFrames and datasets in Java/Scala; SparkSession; a new Accumulator API; a DataFrame-based machine learning API; machine learning pipeline persistence; and distributed algorithms in R.
In order to make Spark faster, Databricks had to rethink how it built the solution’s physical execution layer. Version 2.0 will feature the second generation of the Tungsten engine to focus on modern compilers and MPP databases, as well as an improved Catalyst optimizer.
In addition, the company is shipping Spark 2.0 with the Structured Streaming API, an extension of the DataFrame/Dataset API. The initial version of the API is designed to make Spark smarter and adoption easier.
“Spark users initially came to Spark for its ease of use and performance,” wrote Xin. “Spark 2.0 doubles down on these while extending it to support an even wider range of workloads.”