M2M and connected devices are experiencing renewed interest lately thanks to a relatively recent moniker, “the Internet of things.” But it isn’t just a new name garnering attention.
While every machine has the capability to generate data on its own, the data has been limited to storage within the device for self-action or intelligence. The primary focus to date has been on transferring and sharing data with other devices or systems. According to Machina Research, by 2022, there will be 18 billion M2M connections globally at an annual growth rate of 22%. This many projected connections will generate an astronomical amount of data.
Enterprises invest in M2M to conduct remote monitoring and remote diagnostics of devices. However, they’ve been reluctant to invest in a data warehouse or analytics solution to identify trends for predictive analysis, since most traditional data warehouse solutions are costly and time-consuming. Now, with the availability of Big Data in the cloud, enterprises can get the ROI they need without a huge upfront investment.
While Big Data use cases have revolved around the growing volume, variety and velocity of data, the cloud is more focused on transferring low-byte data in a standard format and less velocity in terms of disk I/O. Considering the availability of Big Data technologies in the cloud, enterprises can finally make M2M analytics a reality.
Look before you leap into M2M
However, M2M does pose inherent challenges. The variety of M2M segments, applications and devices, as well as dynamic and unpredictable traffic, low latency and real-time requirements, all present issues when it comes to building a solution with high throughput and robust data security at a low cost.
To overcome these obstacles and build an M2M analytics solution, enterprise development teams need to gear up for how best to leverage Big Data technologies in the cloud.
Understanding the need for M2M analytics: An important first step is justifying the need for building an M2M analytics solution. Find out who the target users would be and determine the benefits they’ll receive, then identify concrete business use cases in order to define the boundary of the analytics solution:
• Remotely monitor the metrics of M2M applications in real time.
• Analyze machine logs as required to optimize performance or find out the root cause of consumer issues.
• Conduct future forecasting of machine failures using trend and predictive analysis.
• Build a recommendation engine to check usage records for an advertising campaign that can recommend new products, services or plans to consumers.
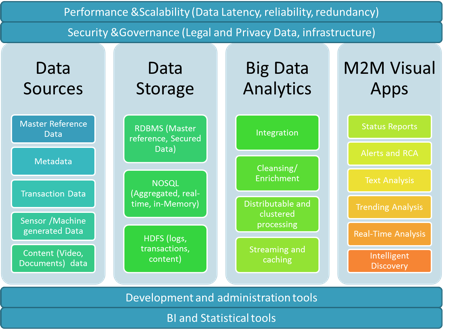
Deciding data sources and targets: Identify data sources for use in data collection and analysis, and output data targets to build a visualization layer for target users. During this phase, it’s important to consider the security and legal aspects of data while finalizing the data sources. In M2M, these data sources will be in semi-structured or unstructured data sources from machines, or sensors containing logs, voice data, images, videos, e-mails, etc. Other prominent internal data sources are ERP and CRM databases containing customer, usage and device records in a structured format.
While deciding on data targets, think about data storage in terms of raw, enriched (transformed) and aggregated data storage and retention policy. Be sure to build reporting interfaces on top of these targets in a way mobile BI users can easily consume for analytics. Stored data should be available using standard APIs to allow seamless integration with fault-management or alert and notification systems.
Choosing a Big Data platform: M2M communication (with its large amount of sensor, image and video data, and machine logs) and traditional data warehouses will be tested against their scaling capability and cost effectiveness. Big Data technology is so much more than a Map/Reduce + an HDFS system; it provides techniques and a platform to build an entire analytics solution. Considerations to keep in mind when choosing a big data platform are:
• Most of the open-source technology is available with dependency on community support and documentation. As of today, however, there is still a lack of development tools. Choose a platform with good community support, active contributing members, and development tools.
• Use technology providing highly distributable processing in memory to reduce disk I/O.
• Evaluate tools for data profiling and transformation to cleanse raw data before loading it into Big Data storage. This is particularly important because Big Data has both structured and unstructured data in massive volumes.
• The analytics solution will likely require the ability to connect with different data sources and targets, so you’ll want to choose technology with built-in connectors to a wide range of front-end query and visualization tools, plus back-end data collection and loading.
Building a proof of concept for M2M analytics solution: To decide whether the technology is suited for the project requirements and use cases, start by building a proof of concept. First, select the basic programming language and frameworks and determine which ones will be best suited. Evaluate the functional object programming language, as code written with it is more concise, elegant and easy for implementing multi-processing logic. Most of these languages interoperate with Java and .NET seamlessly.
M2M requires streaming and caching technologies, so it’s best to evaluate them on non-functional requirements like latency and throughput. Don’t forget that businesses will require highly reliable and zero-fault systems, so look for highly scalable and distributable cluster-based solutions.
Deploying infrastructure on the cloud: Building an M2M analytics solution using Big Data will be more of an on-demand and flexible capacity-provisioning requirement, and these requirements can be short-term. Adding new data centers or hardware for these requirements will be expensive, which is why the cloud becomes the natural choice for building and deploying M2M analytics. When approaching deployment, keep these tips in mind:
• Build APIs to transfer data from each transaction to the cloud for storage and analysis.
• Store M2M data in enterprise systems or local data centers, then replicate the entire data set in batches to the cloud. This involves high latency but affords more control and a more secure environment for enterprise data.
• Store M2M data in enterprise systems, and do general purpose, day-to-day analytics in an on-premise environment. Only send required analysis data over the cloud (to run the algorithm or batch program) when you’re doing batch analytics requiring large numbers of server nodes and processing power. Then send data analysis reports back to the enterprise, where it will be visualized using the on-premise environment. This is useful for a highly secured environment, but has lower costs for analysis.
Hybrid clouds are ideal for M2M analytics because they require analyzing highly secured personal customer data and publicly available censuses, along with social and blog data. Consider using private clouds for customer and billing-related applications, and for storing enterprise data (SQL and NoSQL), as it demands a secure, dedicated performance requirement.
At the same time, consider using public clouds to collect public data, and publish consumer applications and visualization reports on top of analyzed data. Demand for this kind of data fluctuates based on usage and events, which can be easily managed cost-effectively using the public cloud.
Thinking through non-functional aspects: Paying attention to overall performance, scalability, reliability and availability requirements is vital when deciding how best to leverage Big Data for M2M analytics. Deploying and using multi-node clusters with replicating data on multiple nodes will lead to high performance and a reliable system, and since we can expect a large number of clusters, management of the same is also very important. Use built-in administrative tools and, if need be, enhance them for your environment to save time over managing them manually.
For an analytical platform collecting data from multiple enterprises, build a multi-tenancy model. Focus on providing physical databases and logical isolation for consumer and enterprise applications, and don’t forget to define your data retention policy (a necessary step in order to decide the required capacity). When it comes to security, consider the data-retention period and criticality of the data. Define the data security policy in storage, in the network data transfer, and in the access for data reporting, but be aware of increased network security expenditures.
Sunil Agrawal is chief architect of Big Data analytics at Persistent Systems.