
The Heterogeneous System Architecture (HSA) Foundation has announced version 1.0 of its CPU/GPU specification, designed to provide a common framework for developers to create applications to run across PCs, mobile devices, servers, consoles and the Internet of Things running different processors. HSA 1.0 lays out standard guidelines for how “kernel agents” such as GPUs, DSPs … continue reading
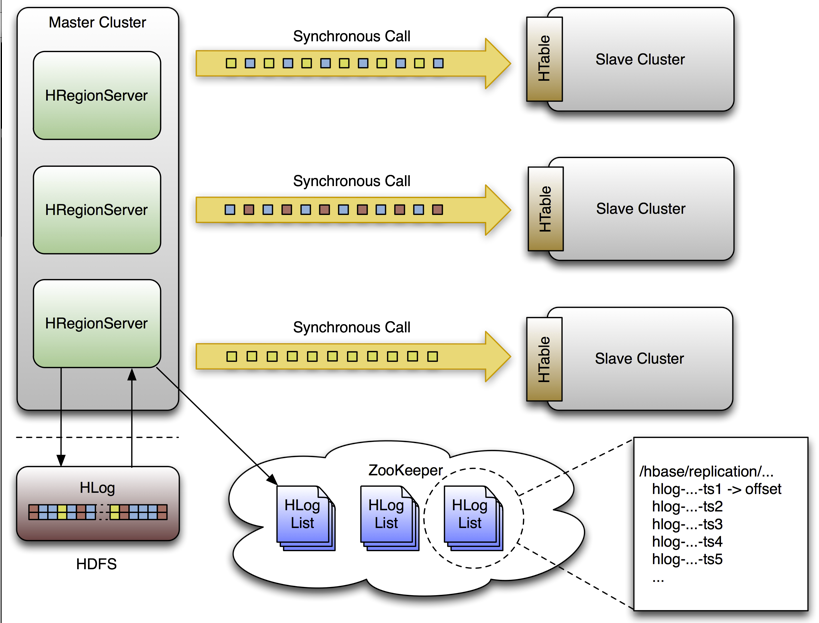
After eight years of development, Apache HBase officially reached version 1.0 yesterday. This stable release includes more than 1,500 bug fixes and changes, and has fully revised documentation. HBase is the database that runs inside of Hadoop, and can be used to store relational data from traditional data stores on the Hadoop File System. Michael … continue reading

The Apache Software Foundation announced the releases of Apache Lucene 5.0 and Apache Solr 5.0, with each project adding new features and major component changes. Apache Lucene 5.0 adds Java’s NIO2 API file access, unique ID storage and IndexWriter merger checking, along with reduced heap storage, auto-IO-throttling and payload support for memory indexes. The full … continue reading

Databricks announces DataFrames for Spark Apache Spark platform provider Databricks has announced DataFrames, a new API for Apache Spark 1.3 designed to simplify distributed data processing for more immediate Spark use. The DataFrames API was built to resemble R and Python data frames, providing a familiar interface for data scientists and building on the Spark … continue reading

Since it was created in 2011, Storm has garnered a lot of attention from the Big Data and stream-processing worlds. In September 2014, the project finally reached top-level status at the Apache Foundation, making 2015 the first full year in which Storm will be considered “enterprise ready.” But that doesn’t mean there’s not still plenty … continue reading
Hadoop has, for the most part, moved beyond the proof-of-concept phase and the initial chasm of adoption. More and more organizations are putting the open-source framework to work on mountains of complex Big Data. The next step in Hadoop’s evolution is getting a handle on governance. To that end, Hortonworks—the enterprise data platform provider and … continue reading

When the Linux Foundation first published its Guide to the Open Cloud in 2013, the pickings were slim and from a bygone era. Today, however, the Guide for 2015 is packed with information on the open-source projects that are quickly becoming part of the new model for cloud software stacks. The 2015 Guide states that … continue reading

The Apache Software Foundation has announced Apache Flink as a Top-Level Project (TLP). Flink is an open-source Big Data system that fuses processing and analysis of both batch and streaming data. The data-processing engine, which offers APIs in Java and Scala as well as specialized APIs for graph processing, is presented as an alternative to … continue reading

The Apache Software Foundation has announced Apache Drill as a Top-Level Project. According to the Foundation, Apache Drill is a schema-free SQL query engine for Hadoop and NoSQL. By removing the constraint of building and maintaining schemas before data can be analyzed, Drill users can run interactive ANSI SQL queries on complex or constantly evolving … continue reading

Conference focuses on the changing use cases Hadoop now handles … continue reading
Skepticism is giving way once developers see what the latest version of Hadoop can do … continue reading
Google launches a developer preview of Chrome apps for the Play Store and Apple App Store … continue reading