
The Apache Foundation this morning announced the promotion of Apache Beam to the top level. That’s good news for the many contributors and users of this unified programming model, which allows them to write batch and streaming jobs at the same time, and to run the resulting artifact on various execution engines. Within the Hadoop … continue reading

Toys that understand a child’s language and interact with him or her on a level he or she can understand. Personal assistants that learn your routines and vocalize reminders to complete tasks, or to exercise. Software quality systems that can learn what is a bug and what is not, or what areas are vulnerable to … continue reading

Artificial intelligence isn’t a new concept. It is something that companies and businesses have been trying to implement (and something that society has feared) for decades. However, with all the recent advancements to democratize artificial intelligence and use it for good, almost every company started to turn to this technology and technique in 2016. The … continue reading
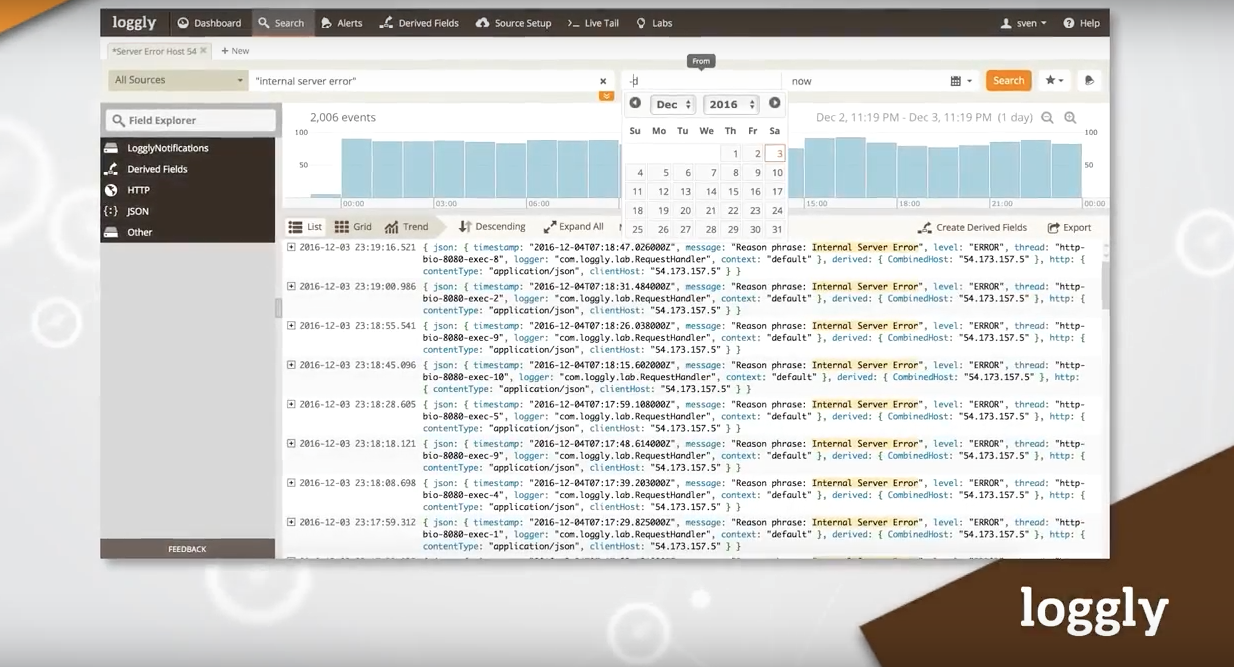
Loggly has introduced Gamut Search, a log analysis technology designed to respond instantly for searches over massive data volumes that span over a long period of time. “Consider that a single movie at TV quality is a gigabyte,” said Charlie Oppenheimer, CEO at Loggly. “Companies are now generating thousands of gigabytes of log data or … continue reading

This month’s column is a transcript of a fascinating conversation I had with MapR executives Jim Scott, the director of enterprise strategy and architecture at Hadoop solution provider MapR, and Jack Norris, senior VP of data and applications, on the subject of microservices and scaling Big Data. SD Times: So, we know that scaling data … continue reading

Work on Apache Arrow has been progressing rapidly since its inception earlier this year, and now Arrow is the open-source standard for columnar in-memory execution, enabling fast vectorized data processing and interoperability across the Big Data ecosystem. Background Apache Parquet is now the de facto standard for columnar storage on disk, and building on that … continue reading

The world increasingly runs on data, and that data is only expanding. Like the blob, it gets everywhere: storage systems, databases, document repositories. According to IDC, the world will hold 44 zettabytes of data by 2020, up from 4.4 zettabytes in 2013. That’s a lot of hard drives. It’s also a recipe for development and … continue reading
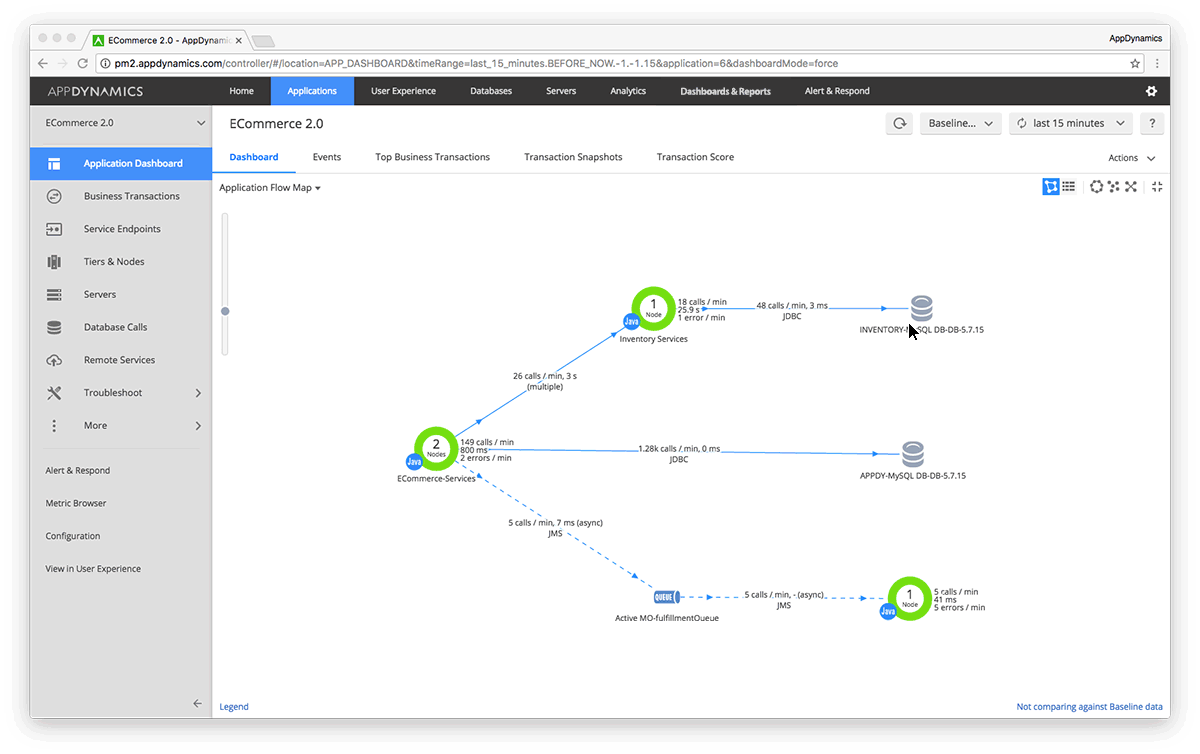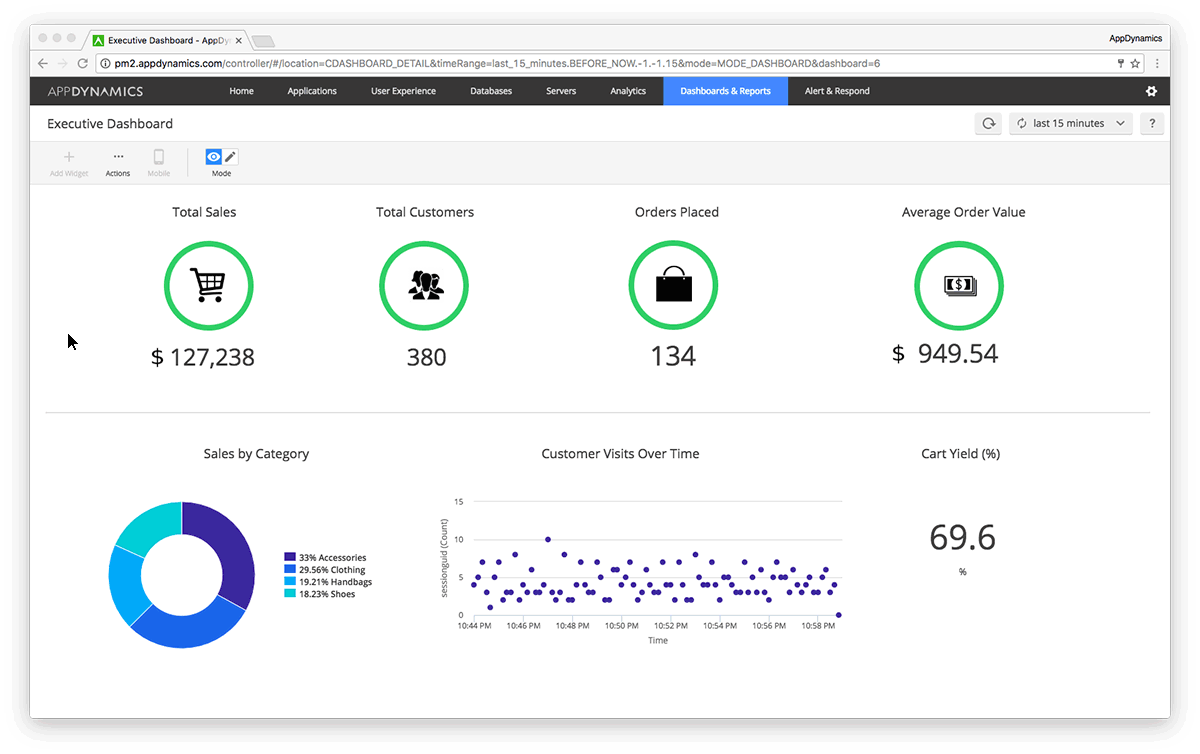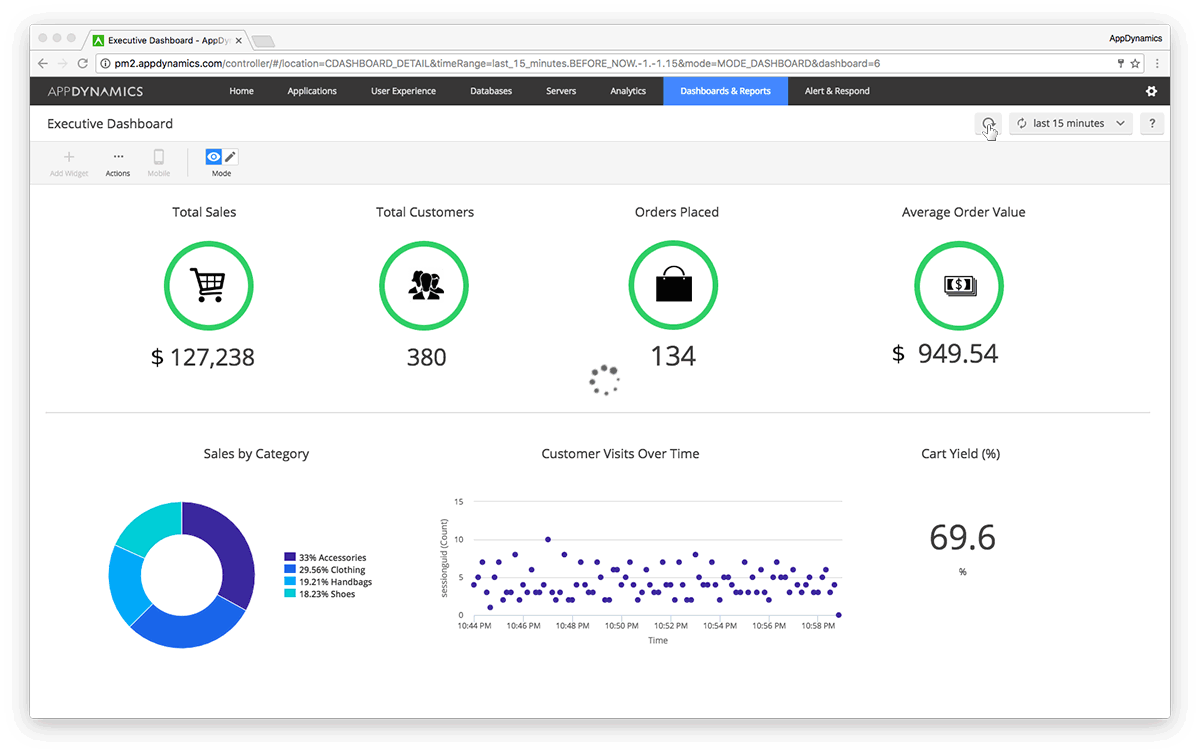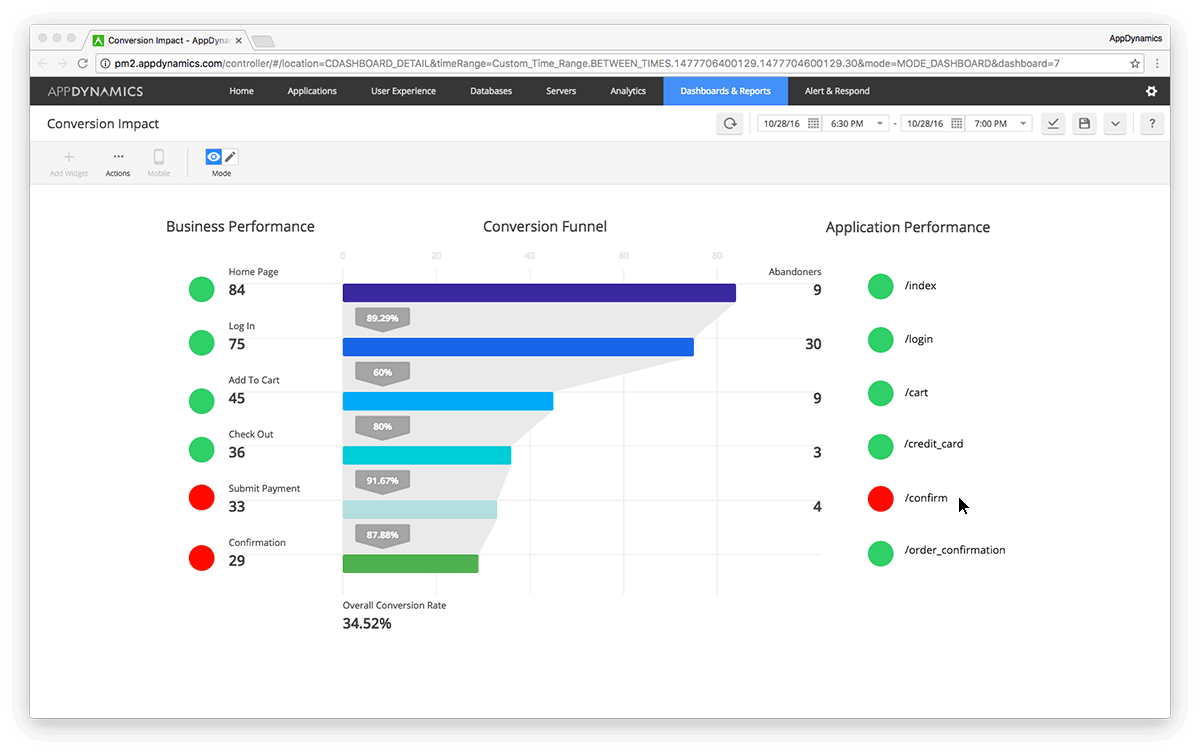
Businesses are learning that they need to work and release software faster in order to use agile infrastructures, but what’s missing from their digital transformation is business leaders and IT teams sharing metrics throughout every phase. In order to connect the dots between the CIOs and IT/operations folks, AppDynamics released its new App iQ performance … continue reading

Big Data is becoming too big to manage manually. The amount of data coming from sensors, streams and social media is astronomical—but that’s only part of the problem. Out of all the data that is being collected, only a small amount of it is actually essential, making it an impossible task to find the needle … continue reading

Altova MissionKit’s latest release features changes to its Big Data, database, and XBRL tools, designed to increase an organization’s productivity. Altova’s last big release was in February, and it focused mostly on support for JSON and .NET APIs, introducing new tools for JSON and features to speed up JSON development. Altova MissionKit 2017 latest updates … continue reading
Apache Spark is reaching more users in new places, according to a recently released report. Databricks announced the results of its second annual Apache Spark survey, which revealed Spark is increasingly being used in the public cloud, streaming and machine learning. “Since inception, Spark’s core mission has been to make Big Data simple and accessible … continue reading

Big Data is changing, but in order for businesses and users to really derive value from it, there needs to be innovative approaches to keep driving it at scale. Strata + Hadoop World kicked off this week with industry thought leaders expressing the requirements needed in today’s Big Data world. Mike Olson, chief strategy officer … continue reading