We test because something broke in the past, because we care about quality code, and we want to make sure the same thing doesn’t happen again. Quality Assurance (QA) testing was a response to the realization that we should proactively seek out problems in our software, before any new code is deployed into production, so that customers are happy.
Today’s cloud-based, distributed architectures are complex and fail in different ways than our resource-limited, highly controlled test or staging environment deployments (much less a monolithic application). Our automated and human QA tests do not account for the rapidly changing production environments of today where services are constantly spinning up and shutting down in response to demand.
RELATED CONTENT:
The role of QA in a shift-left world
Chaos Engineering: Finding outages before they become failures
These distributed systems have emergent behaviors, responding to various production conditions by scaling up and down in order to make sure the application can deliver a seamless experience to increasing customer demands. In other words, these systems never follow the same path to arrive at the customer experience. Emergent behaviors also means emergent failures. Distributed systems will fail, but it’s unlikely that they will fail the same way twice.
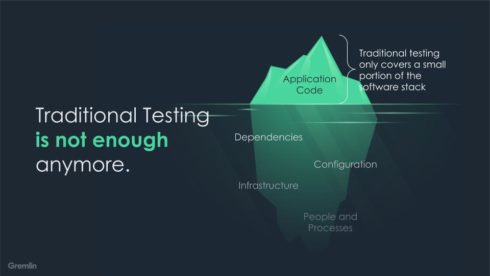
Traditional quality assurance that runs tests at the end of a build and before deployment only covers a very small percentage of our software stack. And no amount of traditional QA testing is going to verify whether our cloud-native application, its various services, or the entire system will respond reliably under any condition, whether “working as designed” or under extreme loads and unusual circumstances.
Whether we practice Site Reliability Engineering, DevOps, or something nameless — all of our critical systems should have uptime objectives. We should be constantly seeking to better understand how our systems handle failure, as well as uncover unforeseen dependencies and issues within our own systems. Traditional QA testing methods will not catch these problems because those methods do not test the entire system as it exists in production. We must expand the scope of our testing and move to a more holistic approach with Chaos Engineering.
Chaos experiments are used to simulate things that we know have caused problems before, such as networking latency. Does the new service hold up under light testing? Medium? Heavy? We increase the testing magnitude and push the new instances hard and in production to have a true understanding of how our systems handle failure where our customers live. This is the only way to find systemic issues in today’s complex reality, regardless of whether we use canary deployments or not.
Chaos Engineering can test the quality of code at runtime, it can test for configuration drift, and it can be used for both automated and manual forms of testing. That makes it a powerful discipline that allows us to proactively seek out systemic issues before those problems cascade into failures that impact customers, doing in the cloud and at scale what we were once able to accomplish with QA in a smaller, more controlled environment with our single monolithic applications.
Start by designing the smallest possible experiment that will teach us something, making sure to keep our systems and data safe while our testing is in progress. When the experiment is complete, examine the monitoring and observability to see what we’ve learned. That data drives how we prioritize our efforts, mitigating small problems before they can become big problems, and handling any big problems that we find immediately. Then we follow up on our work by running the same chaos experiment again in the future, to confirm that the fixes we put in place were effective.
Whatever the solution, we designed it, we implemented it, we performed our automated traditional QA tests, and then we tested it with Chaos Engineering. As a result, it worked as expected when a production failure occurred that was out of our control and, more importantly, our customers never even knew it happened.
Innovation has brought us many great changes and challenges, and the new world is one of complex distributed systems. Our old approach won’t work, but many of the lessons learned still apply. QA people should join the march toward this new paradigm and bring their expertise to help organizations fulfill their mission — providing high quality software that customers love.
KubeConCloudNativeCon in Amsterdam, scheduled for March 30 – April 2, has been postponed.