The DevOps Movement has many recommended practices for automation of processes and testing. However, across different market verticals, the requirements, practices, and cadence of releases very widely. For example, in the more security or safety relevant software markets, development processes often also include compliance to coding standards, or other security and safety practices that must be “baked” into the process in order to achieve compliance.
Where security is involved, we often refer to these extended DevOps automation processes as DevSecOps. Unfortunately, when dealing with massive code bases, the more in-depth practices and development pipelines become quite complex, and, more importantly, time consuming.
Take, for example, the Android (C++ and Java) Android Open Source Project. The project is now used as the base platform for a range of embedded IoT (Internet of Things) devices, including within automotive systems and medical devices – which, on its own, now consists of over 35 million lines of code (MLOC). Or, the Unreal Engine (UE), which is widely used across a broad-spectrum of different tasks in game development, consists of over 3.5 MLOC — and very complex code at that.
With these figures in mind, how can teams that build these modern applications and massive code bases stay agile, while improving the safety, security, and reliability of their systems by making use of DevOps automation?
Introduction to CI/CD
The DevOps Movement is often associated with the principles of Continuous Integration, Delivery, and Deployment.
Continuous Integration (CI) is the practice of automating the integration of code changes from multiple contributors into a single software project. This allows software developers to frequently merge code changes into a central repository where builds and tests are then run.
Automated tools are used to assert the new code’s correctness and ensure no regressions have been introduced before integration. In the event of failures, these changes can be easily and quickly reversed, resulting in greater confidence in each change made to the project.
Continuous Delivery (CD) is an extension of Continuous Integration, whereupon successfully meeting all of the quality and security checks and requirements, the software is automatically packaged. This results in a deployment-ready build artifact that has passed through a standardized test process.
Continuous Deployment (also CD — confusingly) is a further extension of Continuous Delivery where the code changes are then — finally — prepared automatically for a release to the production systems.
A typical CI/CD pipeline will include various phases — or stages — as shown by the visualization below:
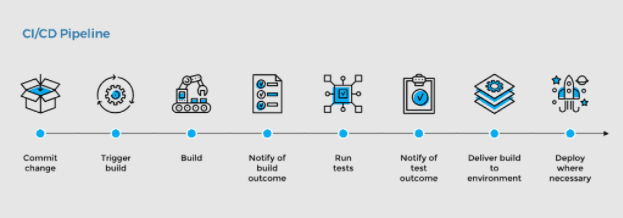
Source: Joseph Evans’ Blog (https://www.jo3-w3b-d3v.com/devops/tools-pipelines)
CI/CD Pipelines
As illustrated above, upon each code change that a developer makes, a CI/CD Job would be initiated through the CI platform (e.g. Jenkins). Based on the outcomes relative to the Build Acceptance Testing (BAT) along with other verification and validation steps, the code changes will either be permitted to merge into the main branch (Master) or be rejected and returned to the committer for further changes.
However, one of the common problems of CI automation is when dealing with large codebases, which causes the CI/CD pipeline execution times to grow — hence feedback times of the success or failure of the commit. As CI/CD pipelines are built out further with code analysis and tests, etc., the problem is only exasperated.
The most obvious solution to this problem is to throw more machine resources at the problem, so that build times — hence feedback times — are reduced to whatever it is that we deem acceptable. But, this is not scalable and — sooner or later — the machinery costs and energy consumption will become impractical. This is where more sophisticated build systems and more modular package structures can help – by building only what is absolutely necessary and ensuring the minimum possible feedback times.
Incremental builds and modular builds are nothing new – the idea of an “update build” is very common for most compiler toolchains. By employing such techniques, we are being far less wasteful in terms of time, computation of resources, and — ultimately — energy, which is very important with the need for us all to reduce our energy consumption and our carbon footprint.
Can we therefore apply the same approaches as we do in compiler technology to our test and analysis steps? For dynamic testing, the answer is usually straightforward; by making a connection (dependency tree) between the test cases and the source code that they are testing, we can be selective as to which test cases are rerun and when. This ensures only those test cases that apply to the changed files are executed in the test stage, and provides the maximum possible efficiency and lowest possible runtimes.
For static analysis tools, more sophisticated examples tend to follow and build-in a similar approach to compiler toolsets by building in dependency-based incremental analysis capabilities.
Incremental and Differential Analysis
Incremental Analysis
Incremental Analysis encompasses the idea of performing an “update analysis”, much like a compiler toolchain will perform an “update build,” as opposed to a full, clean, rebuild. “Analysis objects” contain the analysis data for a module and timestamps or checksums for the files that it depends upon. By maintaining “analysis objects” from a prior analysis build, incremental analysis can initiate a “dependency check” to determine which — if any — of the source files have changed and need to be re-analyzed.
In Incremental Analysis, the whole application is essentially re-analyzed with the minimum effort. Done correctly, Incremental Analysis is much faster than a full analysis with no impact on the accuracy of the results.
However, in a worst-case scenario – imagine that there are code changes for a badly designed system, in addition to an update to a central module or interface that is used (or included) — ultimately — by all other modules in the system. In this instance, the Incremental Analysis time would then be equivalent to the full analysis time.
Sadly, software systems suffering from poor modularity — with unwanted dependencies and couplings — are common and refactoring isn’t always possible. When combined with very large, complex codebases that have very long build and analysis times, this compounds the issues of runtimes for CI/CD pipelines.
Differential Analysis
Put simply, Differential Analysis is an enhanced form of Incremental Analysis, designed for use in CI/CD pipelines, where codebases are large and complex, and build and analysis times are otherwise impractical for “fast feedback” for development teams.
By using system context data from previous full analysis builds on remote build servers, the local static analyzer examines only the files that are new or that have changed as reported by the version control system (e.g. Git or P4). Using this system context data, shared from the servers, the local static code analyzer is able to provide analysis results “as if” your entire system had been analyzed, even though only a small fraction of the system has actually been analyzed locally. Thus, Differential Analysis provides you with the shortest possible analysis times while reporting new issues in the changed code, and can facilitate “fast feedback” to development teams, regardless of the overall scale of the codebase or the lack of modularity in its design.
For static code analysis tools like Klocwork, Differential Analysis will also only report the new issues that were detected since the last build, or with respect to the current main branch. This helps ensure that their focus is maintained on the “new issues” that will degrade the quality of the codebase and lead to issues with compliance.
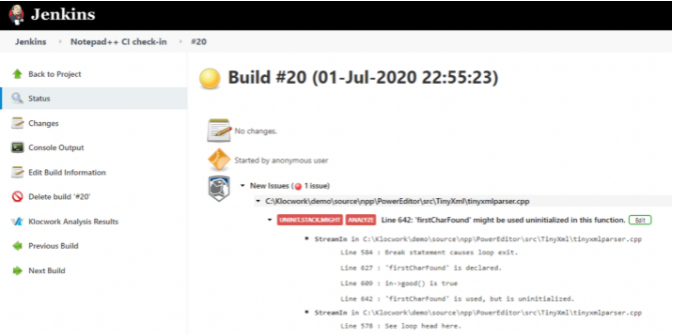
Source: Perforce (Sample Differential Analysis output in the Jenkins console)
Use Cases for Differential and Incremental Analysis
When trying to understand where developers would get the most value out of Incremental or Differential Analysis, it is important to consider the feedback times required for the developers to remain productive. Then balance that with the constraints created by the code base size and complexity, and the numbers of changes and commits being made since the previous build.
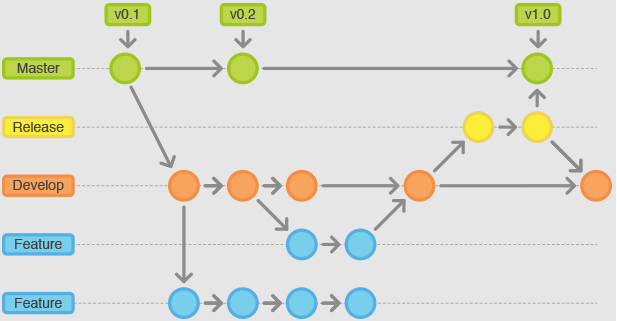
Source: Feature and Master Branches: StackOverflow (https://stackoverflow.com/questions/20755434/what-is-the-master-branch-and-release-branch-for)
Feature Branch CI Pipeline
Within a feature branch, as illustrated above, a developer typically would commit several versions of their branch and a CI job would run with each commit. In this case, Differential Analysis will save considerable time, and provide fast feedback and focused results based on the changes.
Differential Analysis will report the new issues or vulnerabilities in a specific change set of files (a subset of the application). For smaller applications, where build and analysis times are less of an issue, the entire application could be analyzed with each commit. Either way, this approach will benefit the development teams by reducing the number of issues merged to the main branch.
Develop Branch CI Pipeline
Within development teams where there are multiple developers, each working on their own branch. Post successful commits of the Feature branches, a further CI pipeline execution may be initiated for the Dev branch, prior to merging all of the changes to the Release branch. An Incremental Analysis would be extremely beneficial here, since it will carry all of the changes made by the various Feature branches and analyse them “incrementally” compared to the previous Release branch revision code. In many cases, where codebases are large and complex, this would save a tremendous amount of time, whilst still providing analysis results that are consistent with a full, clean build.
Additionally, as developers make daily changes to the Feature branches that end up eventually merged into the Dev branch, it is critical to have a cadence of re-establishing the most up-to-date system context data available, so that the next differential analysis runs performed on new Feature branches are as relevant and correct as possible.
Release Branch CD Pipeline
Finally, with the creation of each release candidate upon the Release stream, it is usually recommended that a full, clean analysis is run to ensure that the most accurate analysis data is provided for the whole application, and with no interference from previous runs. This independence is often a requirement of safety and security standards in producing the final policy scan results and compliance reports.
The Bottom Line
Maturing software development can be accomplished through established DevOps principles of automation and optimization. As highlighted in this article, the DevOps pipeline consists of recurring stages.
By reducing the overhead and unnecessary rework within these stages through methods like Differential and Incremental Analysis, automation of code reviews, and dependency-based rerunning of dynamic test cases, developers can move much faster — without compromising the security, quality, and safety of their end product. In all cases, the use of CI techniques to encourage detection — and ideally remediation — of new issues as early as possible in the software development life cycle can only improve development productivity.
Content provided by SD Times and Perforce Software. About the co-authors: Eran Kinsbruner is chief evangelist, SAST & DevOps, and senior director of Product Marketing at Perforce; and Steve Howard is static analysis specialist and technical services lead at Perforce.