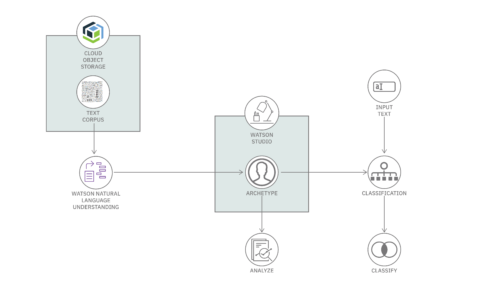
IBM wants to help developers identify and classify archietypes in data with the release of a new code pattern.
Archetypes are formally defined as a pattern, or a model, of which all things of the same type are copied. According to the company, its Watson natural language understanding helps users discover archetypes in their text corpus.
“When we read through a set of these records, our mind naturally groups the records into some collection of archetypes. For example, we may sort a song collection into easy listening, classical, rock, etc. This manual process is practical for a small number of records (e.g., a few dozen). Large systems can have millions of records, so we need an automated way to process them,” IBM wrote in a blog post.
Because records are often presented in unstructured text, automated processing needs to be able to understand natural language, which is why Watson Natural Language Understanding was built, IBM continued.
The code pattern, which can be found on GitHub, coupled with statistical techniques, can help users discover meaningful archetypes in their records and classify new records against this set of archetypes.
The user can interact with the Watson natural language understanding service through the provided application user interface or the Jupyter Notebook, can run a series of statistical analysis on the result, use the graphical display to explore the archetypes and classify a new dictation.
The full details on the capabilities of the code pattern are available here.




