
MapR Technologies wants to further Big Data containerization in the enterprise. The company has announced an updated version of its MapR Converged Data Platform that provides new advances for containers such as persistent storage and integrated resource management. The MapR Platform also introduces Apache Myriad, an open-source project designed to remove barriers between resources managed … continue reading

Google’s artificial intelligence system from Google’s DeepMind unit will try to beat the very top player in the ancient Chinese board game of Go, starting tomorrow. The contest will be livestreamed on DeepMind’s YouTube channel. The five matches can be watched on March 8, 9, 11, 12 and 14. Starting at 8 pm Pacific Time, … continue reading

If you haven’t heard of polyglot persistence before, simply put, it means using different database technologies to handle specific needs. The term was derived from something else you may have heard: polyglot programming, which expresses the idea that applications should be written in a mix of languages to take advantage of the fact that different … continue reading

The Internet disrupts every industry, and business intelligence (BI) is no exception. As modern Web applications voraciously consume data, they blast past the bounds of traditional relational databases. Scaling out mushrooming data sets with replication, caching, tuning, hardware and sharding solutions is one way to go, but more than ever, flexible NoSQL data stores like … continue reading

Companies are collecting, generating, storing and analyzing more data than ever before to improve their competitive standing. However, organizations vary significantly in their ability to leverage information across the enterprise and even between departments such as marketing and sales. All too often, available data, reports and analytics aren’t being leveraged as effectively as they could … continue reading

Yahoo has released CaffeOnSpark, which brings the fruits of two University of California, Berkeley projects together: vision-focused deep learning framework Caffe, and Big Data processing engine Apache Spark. Without the aid of Spark, Caffe can process up to 60 million images per day. Those numbers come from benchmarks on a single NVIDIA GPU, so the … continue reading
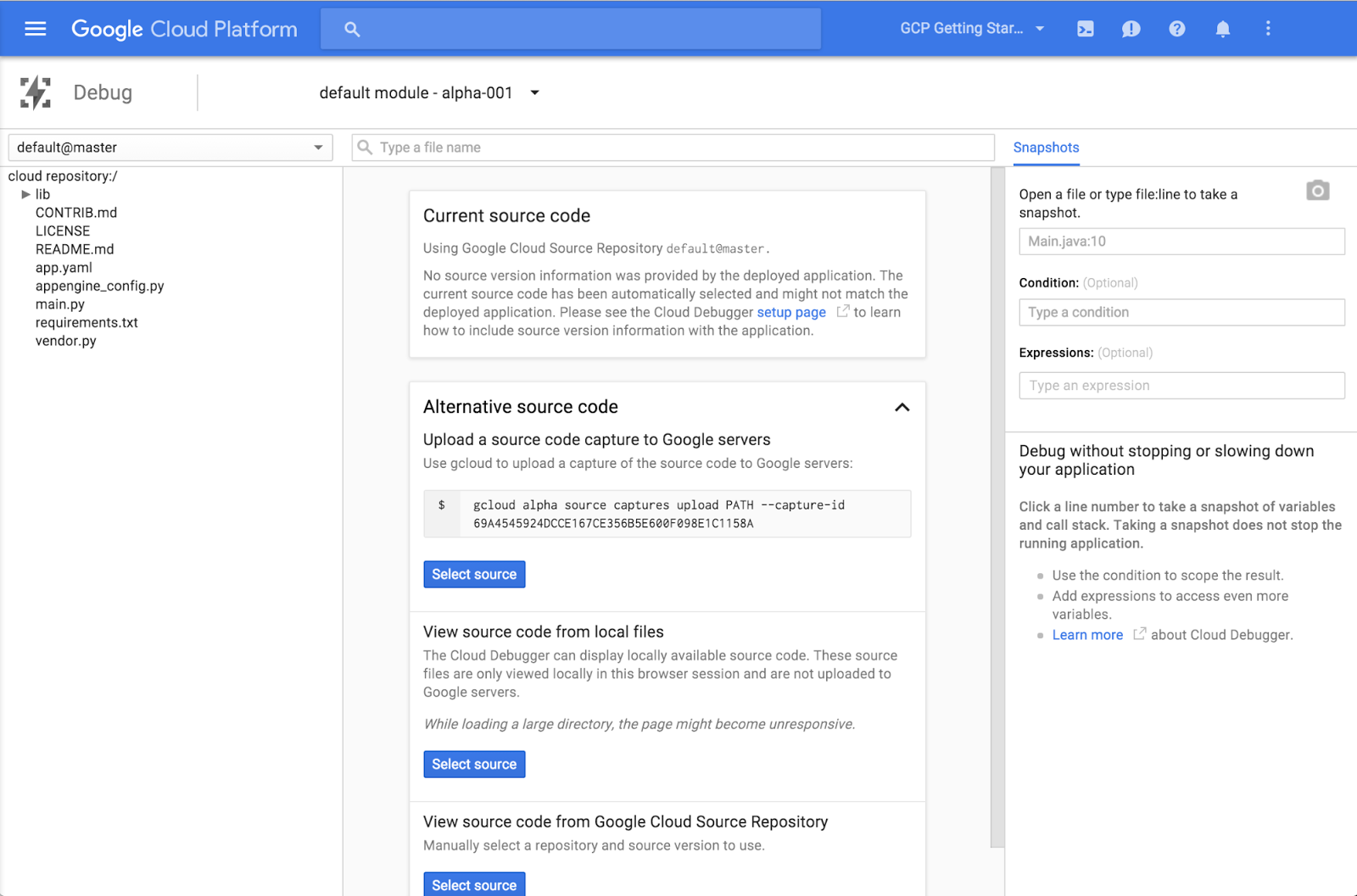
Google Cloud Debugger lets developers inspect the state of an application at any code location without stopping or slowing it down. It now has an enhanced UI, expanded language support, and debugging from more places, according to the Google Cloud Platform blog. This can be viewed in the application state without adding logging statements, and … continue reading

Wikibon, a community formed to help solve technology problems, has released what it says is the first-ever Spark forecast that shows how Spark is changing the industry. “Our report is the first to show how Spark is remaking the marketplace, presenting not just numbers of users, but also data about what vendors are building and … continue reading
The database revolution happened a few years back, when NoSQL options stormed the world. Today, however, a second wave of innovation in data storage has been unleashed in the form of Apache Arrow. Arrow builds a standard for columnar in-memory analytics, and will provide a unified data structure, algorithms and cross-language bindings. The overall goal … continue reading

The Khronos Group has announced the immediate availability of Vulkan 1.0, a royalty-free open standard API specification. Vulkan has been in the making for 18 months, and is designed to provide high-efficiency, cross-platform access to graphics and compute on modern GPUs used in a wide variety of devices such as PCs, consoles, mobile phones and … continue reading

Shares of Alphabet, Google’s holding company, opened nearly three percent higher today, pushing it past Apple. This makes Alphabet the most valuable public company, according to a report by CNBC. Alphabet has a market cap of US$547.1 billion, which is higher than Apple’s $529.3 billion. The last time Google was more valuable than Apple was … continue reading

The Apache Hadoop project took off in enterprises over a fairly short period of time. Four or five years ago, Hadoop was just becoming a “thing” for enterprise data processing and experimentation. MapReduce was at the heart of that thing, and Spark was still only a research project at the University of California at Berkeley. … continue reading