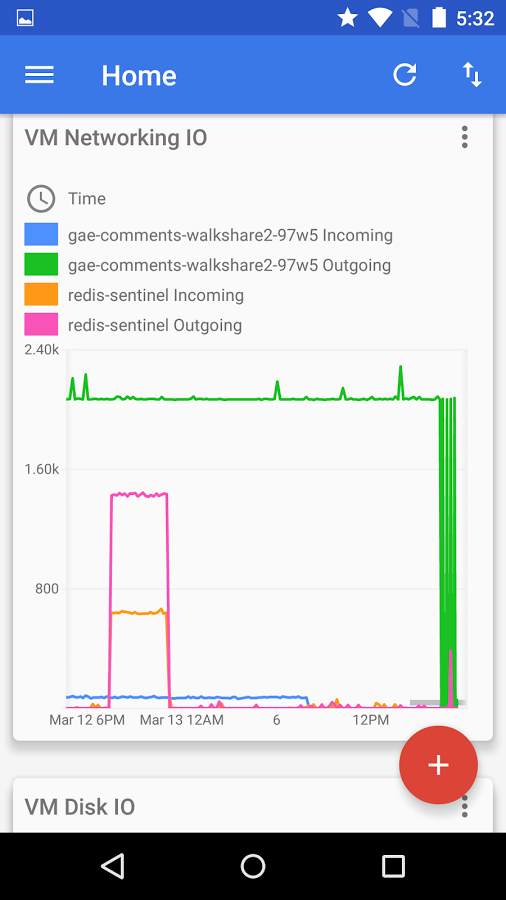
Google has announced the new Google Cloud Console, a mobile app for Android and iOS to help developers manage cloud platform resources from their devices. Google Cloud Console lets developers view the overall health of their system, view projects, set alerts, monitor billing, and manage Google Cloud Platform resources. The console has the ability to … continue reading

At what stage is your Hadoop deployment? Is it still in the planning stages, in the lab, in development, in production or already making you money? Or is it still hiding under your desk? Let us know, and feel free to expand on your answer in the Comments section of this article! Where is your … continue reading
You want to keep your hot data hot and your cold data cold. That’s the idea behind a data-access-management patent issued to Zettaset on June 23. The new technology, dubbed “DiamondLane” by the company, allows administrators and developers to prioritize the storage of data based on its “temperature.” That temperature setting amounts to varying degrees … continue reading

Snowflake Computing, the cloud data warehousing startup that emerged from stealth mode last year, has announced the general availability of Snowflake Elastic Data Warehouse, along with US$45 million in Series C funding. Snowflake views data warehousing as a software service, mixing structured and unstructured data in a virtual cloud warehousing architecture with querying and analytics … continue reading

Databricks has announced the general availability of its cloud-hosted data platform, formerly known as Databricks Cloud. Less than a week after announcing the release of Apache Spark 1.4, Databricks debuted its cloud platform at Spark Summit, which has support for R-language notebooks; version-control and source-code change tracking from within Databricks; private notebook permissions management; and … continue reading

IBM is looking to accelerate innovation for the Spark ecosystem with its latest commitments to the open-source project. According to the company, the Big Data processing engine is potentially the most significant open-source project of the decade. “Spark is undoubtedly a force to be reckoned with in the Big Data ecosystem,” said Beth Smith, general … continue reading

Databricks has announced the general availability of Apache Spark 1.4, including SparkR, a new R API for data scientists. Version 1.4 of the open-source Big Data processing and streaming engine also enhances Spark’s DataFrame API features, Python 3 support, a component upgrade past alpha for Spark’s machine learning pipeline, and new visualization and monitoring capabilities … continue reading

Data application infrastructure provider Concurrent has announced general availability of Cascading 3.0. The latest version of the enterprise Hadoop application development and deployment platform improves portability across programming languages such as Java, Scala and SQL, and across Hadoop distributions such as Cloudera, Hortonworks, MapR. And it now has native support for compute fabrics like Apache … continue reading

MapR announced the release of MapR 5.0, along with new auto-provisioning templates for data lake deployment, interactive SQL data exploration, and operational analytics at Hadoop Summit. Version 5.0 of the MapR Hadoop distribution adds a new Views feature for the newly released Apache Drill 1.1 for agile data governance, and granular access controls for better … continue reading

Couchbase is rolling out a new SQL query language that gives developers the ability to combine JSON data modeling with declarative SQL queries for NoSQL data. The NoSQL database platform provider announced a beta of the N1QL language as part of Couchbase Server 4.0. According to Couchbase CEO Bob Wiederhold, N1QL is a NoSQL query … continue reading

Datameer, the only proven big data insights platform for rapid data discovery, today announced new data governance capabilities for its native Hadoop environment. As a pioneer in big data analytics, Datameer is helping solidify Hadoop as a mature and transparent platform for production-ready, mission-critical and regulatory-compliant analytics use cases. While big data analytics is enabling … continue reading

Ted Dunning, the newly appointed vice president of the Apache Incubator, is a Big Data scientist in a world of coders. Currently the chief application architect at Hadoop distribution company MapR, the longtime Apache Software Foundation contributor and project mentor took over as the ASF’s vice president of incubation in April. Tasked with keeping Apache … continue reading