
Did you hear about the hacking attack carried out a few years ago on AT&T that resulted in exposing the contact details of more than 100,000 iPad users that were stored on their system? It was one of the high-profile attacks that targeted a “security misconfiguration” vulnerability in AT&T’s system architecture. That was not a … continue reading

LexisNexis is a provider of legal, government, business and high-tech information sources. The group is also responsible for HPCC Systems (High Performance Computer Cluster), a massive, open-source parallel-processing computing platform for the world of Big Data. It’s also made its way into this week’s featured GitHub project. The Big Data tool was open-sourced in 2011 … continue reading

HTC announced the VR Venture Capital Alliance (VRVCA), a US$10 billion initiative that will put investments into long-term growth in the virtual reality industry. The VRVCA is made up of 30 virtual reality investors from all over the world. They believe that virtual reality is a “transformative technology that will revolutionize entire industries, one that … continue reading

The Apache Hadoop project has long been big enough for its own conference, this time in its ninth year. During the keynote at Hadoop Summit from Hortonworks’ cofounder and chief architect Arun Murthy, the company detailed its plans to improve the security, governance and ease of use of the Hadoop platform and its ancillary support … continue reading

MongoDB wants to empower developers to do more with its NoSQL database. The company unveiled MongoDB Atlas and MongoDB Connector for Apache Spark at its third annual MongoDB World conference in New York City today. “When people free their mind and focus on the problem or task at hand, you can do your best thinking,” … continue reading

You can’t deal with Big Data that is also real-time data without feeling overwhelmed. It’s as if money were falling from the sky at an ever-faster rate, and you were scrambling to capture it all without worrying about which bills might be counterfeit. You want to be able to sort out what’s important later rather … continue reading

The Spark Summit kicked off this week in San Francisco with companies releasing new solutions designed to make it easier to work with Apache Spark. Databricks, the creator of Apache Spark, announced the general availability of the Databricks Community Edition (DCE). DCE is a free version of its data platform built on top of Apache … continue reading

It’s one thing for organizations to look at periodic alerts from their IT infrastructure, triage them and then remediate the problem (if necessary). In today’s Big Data world, though, there might be as many as 70,000 alerts coming through. That makes effective response nearly impossible. Assaf Resnick recognized this problem when he founded BigPanda in … continue reading
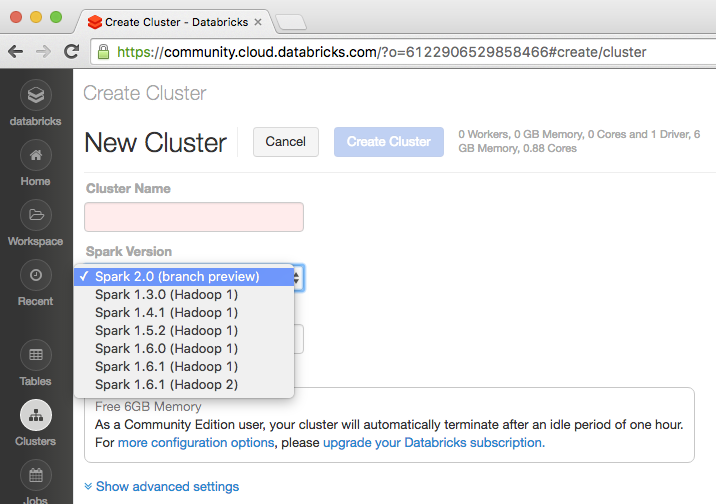
It’s been two years since Apache Spark 1.0 was released, and today Databricks is giving everyone a preview for what is to come in version 2.0. According to the company, the upcoming version focuses on three major themes: easier, faster and smarter. “Spark 2.0 builds on what we have learned in the past two years, … continue reading

MapR, a converged data platform, and Pluralsight, an online learning platform, both announced new curriculum offerings for developers who want to learn new skills in either Apache Kafka or Java. MapR is now offering stream processing training on MapR Academy’s free On-Demand Training program. This is designed to teach developers how they can extend their … continue reading

Jay Kreps, the creator of Kafka, gave the keynote yesterday at the first Kafka Summit in San Francisco, where attendees learned about this Apache real-time stream processing platform and how fast it is growing. Originally built by Kreps at LinkedIn, Kafka has grown to become one of the most popular stream processing platforms out there. … continue reading

The Apache Apex project has been promoted from the Apache Incubator to becoming top-level project as of today. This open-source stream- and batch-processing platform works with YARN and HDFS, runs in memory, and can handle event processing and fault tolerance. Apex started out as the real-time streaming core of DataTorrent. The company contributed its platform … continue reading