GraphRAG is an open source research project out of Microsoft for creating knowledge graphs from datasets that can be used in retrieval-augmented generation (RAG).
RAG is an approach in which data is fed into an LLM to give more accurate responses. For instance, a company might use RAG to be able to use its own private data in a generative AI app so that employees can get responses specific to their company’s own data, such as HR policies, sales data, etc.
How GraphRAG works is that the LLM creates the knowledge graph by processing the private dataset and creating references to entities and relationships in the source data. Then the knowledge graph is used to create a bottom-up clustering where data is organized into semantic clusters. At query time, both the knowledge graph and the clusters are provided to the LLM context window.
According to Microsoft researchers, it performs well in two areas that baseline RAG typically struggles with: connecting the dots between information and summarizing large data collections.
As a test of GraphRAG’s effectiveness, the researchers used the Violent Incident Information from News Articles (VIINA) dataset, which compiles information from news reports on the war in Ukraine. This was chosen because of its complexity, presence of differing opinions and partial information, and its recency, meaning it wouldn’t be included in the LLM’s training dataset.
Both the baseline RAG and GraphRAG were able to answer the question “What is Novorossiya?” Only GraphRAG was able to answer the follow-up question “What has Novorossiya done?”
“Baseline RAG fails to answer this question. Looking at the source documents inserted into the context window, none of the text segments discuss Novorossiya, resulting in this failure. In comparison, the GraphRAG approach discovered an entity in the query, Novorossiya. This allows the LLM to ground itself in the graph and results in a superior answer that contains provenance through links to the original supporting text,” the researchers wrote in a blog post.
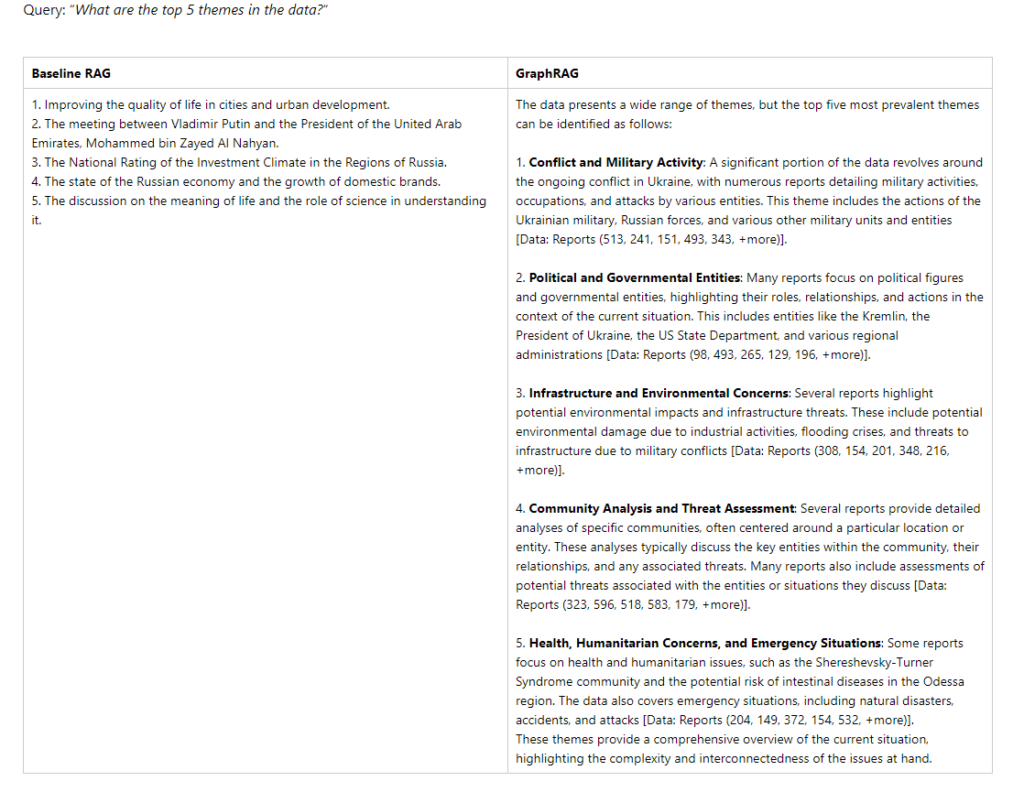
The second area that GraphRAG succeeds at is summarizing large datasets. Using the same VIINA dataset, the researchers ask the question “What are the top 5 themes in the data?” Baseline RAG returns back five items about Russia in general with no relation to the conflict, while GraphRAG returns much more detailed answers that more closely reflect the themes of the dataset.
“By combining LLM-generated knowledge graphs and graph machine learning, GraphRAG enables us to answer important classes of questions that we cannot attempt with baseline RAG alone. We have seen promising results after applying this technology to a variety of scenarios, including social media, news articles, workplace productivity, and chemistry. Looking forward, we plan to work closely with customers on a variety of new domains as we continue to apply this technology while working on metrics and robust evaluation. We look forward to sharing more as our research continues,” the researchers wrote.
Read about other recent Open-Source Projects of the Week:



